[ECCV2024 poster] The First to Know: How Token Distributions Reveal Hidden Knowledge in Large Vision-Language Models?
很有趣的工作. 生成的第一个 token 其 embedding 具有丰富的信息量来判断是否正在生成不安全的内容. 这篇文章是多模态领域的, 但 NLP 也有类似的观察了. 作者拿输出层的第一个 token 的 logit 作为特征向量, 用特征向量训练一个线性分类器以预测行为的性质. 在不同 prompts 上都有鲁棒性, 而且使用后面 token 的 logit 效果不如前面 token 的效果
在数学问题, 幻觉问题, 图像分类问题上实验都有不错的效果, 微调后的效果不如线性探测, 而且微调后的线性探测能力会减弱
Linear Probing:
For a specific task, we have a train set and a test set. Each sample is an imagetext pair, e.g., an image of a dog and a question regarding the color of the dog. We feed the training samples into an LVLM and extract the logit distribution corresponding to each output token, and train a linear classifier model Pθ with learnable parameters θ on the logits. Then, we evaluate Pθ on the test set.
In experiments, we evaluate seven different LVLMs in three tasks with varying prompt designs. We will demonstrate that the logit distribution of the very first token proves to be highly beneficial across a variety of tasks, including recognizing unanswerable visual questions, defending against multi-modal jailbreaking attacks, and identifying deceptive questions. The usefulness of the “first logits” will be validated across different models, tasks and prompts.
后续生成 token 用来线性探测效果不好, 原因是模型对其生成变得更加自信, logit 包含的信息较少. 但是用最后一个 token 的 logit 也有不错的效果, 原因是最后一个 token 是
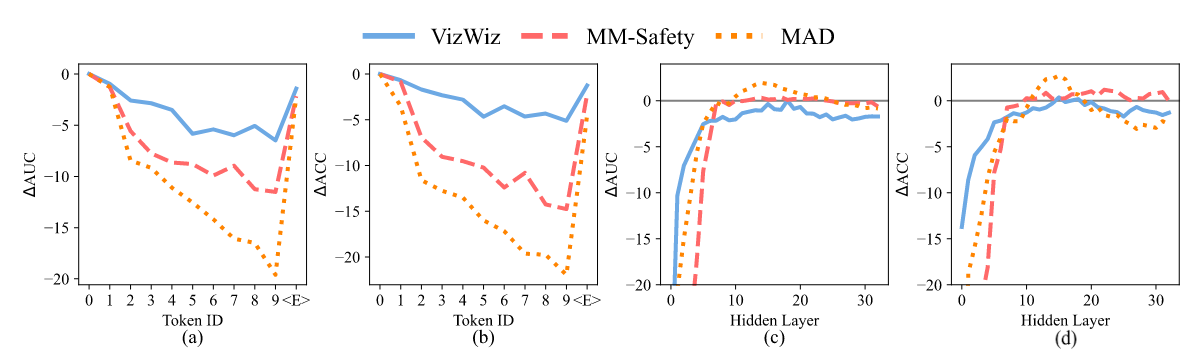
基于以上发现, 作者改变了解码过程, 生成第一个 token 后将 logit 输入训练好的线性分类器中, 如果检测结果为有害, 则使用设定好的模板答案来替换原始的第一个 token, 然后继续生成答案.
训练完线性分类器后, 增加的推理成本可忽略不计. 缺点在于, 作者定义的线性分类器是 task-specific 的, 比较僵硬, 没有那么优雅