InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks
Introduction
- Vision Encoder 和 LLM 参数量相当
- 多语言一致性表示 (就是简单使用 LLaMA 初始化)
- 渐进式的模态对齐方法, 先通过对比学习 pretrain, 然后过渡到对不同细粒度数据的学习
Related Work
目前的 Vision Encoder 来自 ImageNet 或 JFT 等纯视觉数据集, 或对比学习得到的 ViT, 而且 Vision Encoder 的规模较小.
Proposed Method
Overall Architecture
InternVL 使用类似 LLaVA 的结构
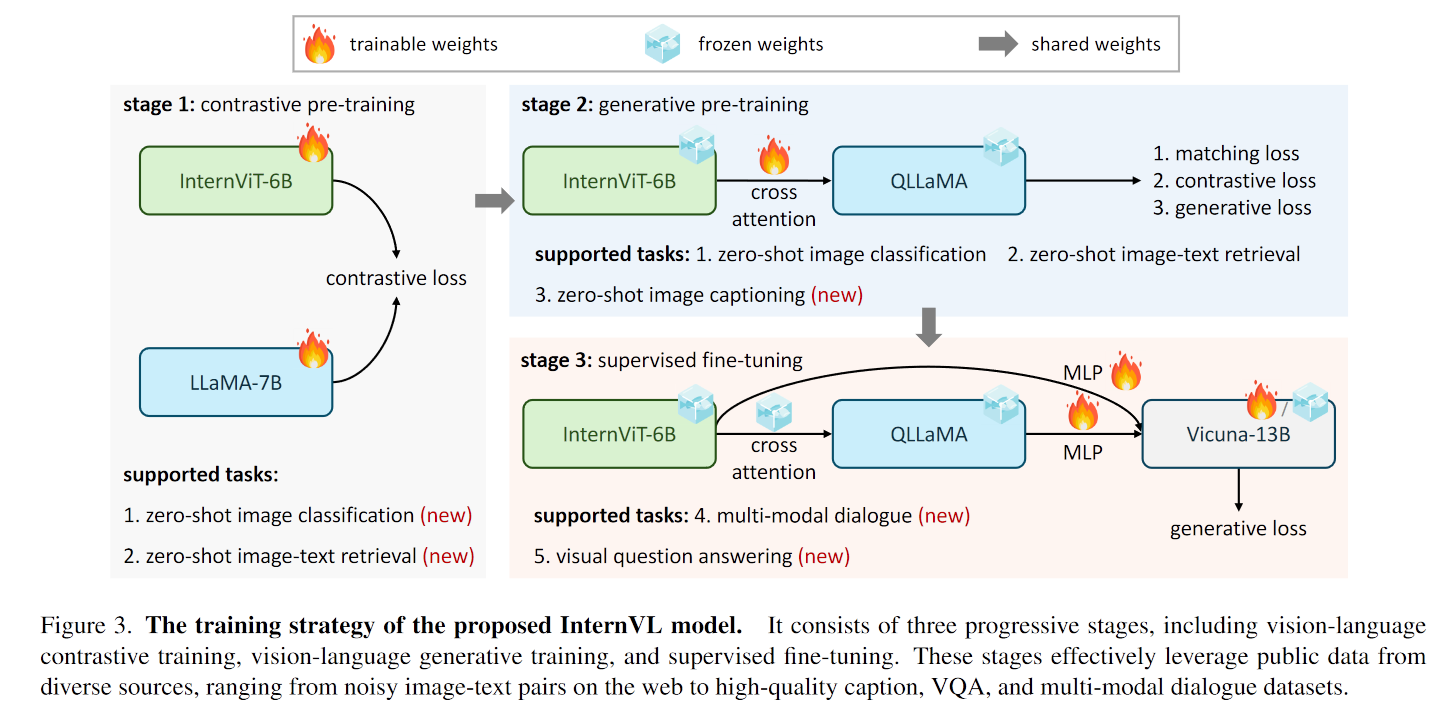
As depicted in Figure 3, unlike traditional vision-only backbones [57, 94, 148] and dual-encoder models [67, 117, 130], the proposed InternVL is designed with a vision encoder InternViT-6B and a language middleware QLLaMA.
提出 QLLaMA 作为 projector
引入了渐进式模态对齐策略
Model Design
-
Large-Scale Vision Encoder: InternViT-6B
为了和 LLMs 的尺度匹配, scale up 到 6B, 使用对比学习在 LAION-en 数据集的 100M 子集上训练
-
Language Middleware: QLLaMA
QLLaMA 是在 LLaMA 基础上, 使用 learnable queries 和 cross attention 训练得到的. QLLaMA 用于对齐模态, 大小为 8B
-
“Swiss Army Knife” Model: InternVL
灵活使用 InternViT-6B, QLLaMA 和 learnable queries, 可以完成各种任务
Alignment Strategy
- 对比学习, 将 InternViT 与 LLaMA-7B 对齐 (与CLIP 训练方法相同), 二者都训练
- 使用生成式任务训练. 将 InternViT 与 QLLaMA (也即第一阶段中训练后的 LLaMA) 串联, 二者间加入 cross attention, 并使用 learnable queries (这里训练使用的任务都是同时使用 learnable queries 和 cross attention 的). 这里与 BLIP-2 的训练方法相似
- SFT. 将 InternViT 与 QLLaMA 与 LLM 通过 MLP 连接在一起, SFT 训练. 由于 QLLaMA 与 LLMs 原本就处于同一特征空间, 所以此时仅训练 LLMs 和 MLP 即可
How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites
Introduction
优点:
-
Flexible Resolution
-
Bilingual Proficiency
卓越的中英双语能力
-
Strong Visual Representation
增强了 InternViT-6B 的视觉表示能力
Related Work
既有多模态大模型通常在较小的固定分辨率上训练, 这导致在不常见的长宽比或文档数据的图像上表现不佳. 为了解决以上问题, 常见的技术路线有
- 双分支图像编码器
- 高分辨率划分为多个低分辨率
InternVL 1.5
Overall Architecture
结构与 LLaVA 类似, “InternViT-6B-MLP-InternLM2-20B”
训练中将图片分别多个 448*448 的图像块, 为了进一步减少 vision token, 使用 pixelshuffle 减少 vision token 数量, 将 448*448 的图像块变为 256 vision tokens
Strong Vision Encoder
丢弃了 InternViT-6B 的最后三层, 从 48 层减少到 45 层
Dynamic High-Resolution
受到 UReader 的启发, 采用动态高分辨率训练方法
-
Dynamic Aspect Ratio Matching
保持自然的宽高比, 从预定义的宽高比中动态匹配最佳的宽高比
-
Image Division & Thumbnail
确定适合的宽高比后, 图像大小被调整成响应的分辨率. 800*1300 -> 896*1344 -> 多个448*448. 再用一个大小为 448*448 的缩略图捕获全局上下文. 所以训练时一共有 256*(12+1)=3328 个 vision tokens, 测试时最多有 256*(40+1)=10496 个 vision tokens
High-Quality Bilingual Dataset
Experiments
InternVL2
技术报告待公布