语言模型
语言模型的定义是一种对令牌序列 (token) 的概率分布, 每个 token 被分配一个概率
自回归语言模型 (Autoregressive language models)
序列 的联合分布 的常见写法是使用概率的链式法则:
在自回归语言模型 中生成整个序列 , 需要逐 token 生成, 每个 token 基于之前生成的 token 计算获得
其中, 是一个控制我们希望从语言模型中得到多少随机性的温度参数
- T=0: 确定性地在每个位置 i 选择最可能的 token
- T=1: 从纯语言模型 “正常 (normally)” 采样
- T=: 从整个词汇表上的均匀分布中采样
加速推理
KV cache
设输入序列长度为 s, 输出序列长度为 n, 模型深度为 l, 维度为 h, 以 FP16 来保存 KV cache, KV cache 的峰值显存占用大小为
这里第一个 2 表示 K/V, 第二个 2 表示 FP16 占 2 bytes.
以 GPT3(175B) 为例, 对比 KV cache 与模型参数占用显存的大小, 已知 GPT3 weight 占用显存大小为 350 GB(FP16), 层数l=96, 维度h=12888
| batch size | s+n | KV cache(GB) | KV cache/weight |
|---|---|---|---|
| 4 | 4096 | 75.5 | 0.22 |
| 16 | 4096 | 302 | 0.86 |
| 64 | 4096 | 1208 | 3.45 |
随着 bs 和长度 l 的增大, KV cache 占用的显存开销快速增大, 甚至超过模型本身.
优化 KV cache 的必要性:
- LLM 的窗口长度不断增大, 出现 LLM 窗口长度的增长需要与 GPU 显存有限间的矛盾. (以OpenAI API为例, 输出 token 其实比输出 token 更长)
- 消费级显卡上, 显存容量小, KV cache 在一定程度上降低了模型的 bs, KV cache 优化在工程落地中更显重要
- 部分文生视频或文生图的模型从 U-Net 转向 DIF (diffusion transformer) 架构, KV cache 可以起到类似 LLM 上的加速效果
KV cache 的作用
prefill 阶段: 输入问题 “what is the apples”, 返回了第一个 token “Apples”, 同时初始化 kv cache
decode 阶段: 输入单个词 q, 通过自回归的方式, 生成 “Apples are a boring fruit” 句子. 过程中 q 的长度为 1, 即当前词, 返回下一个词, 同时更新 kv cache
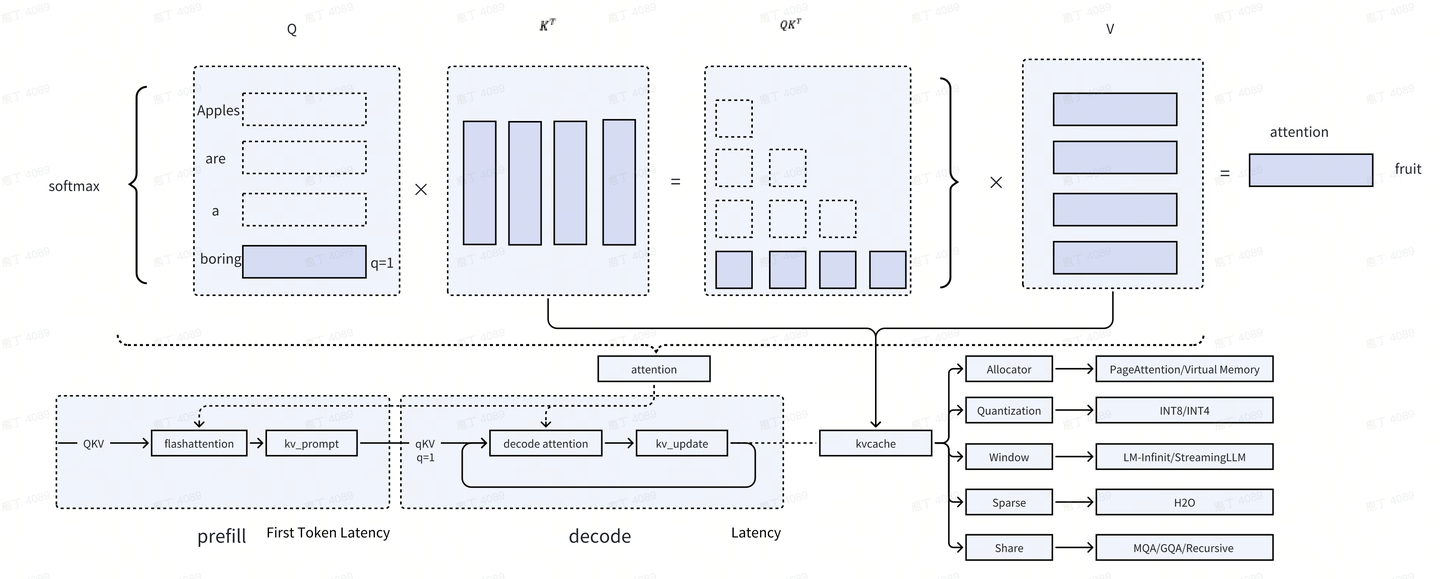
如图所示, kv cache 是 attention 计算中的全量 kv 缓存, 主要作用在 decode 阶段, 目的是将输入 Q 优化为输入 q