强化学习笔记
参考博客:
强化学习的基本概念
强化学习的基本组成
- 智能体 agent: 我们训练的模型
- 行为 action: 模型操作
- 环境 environment: 提供 reward 的某个对象
- 状态 state: 环境的状态
- 奖励 reward: 在明确目标的情况下, 接近目标意味做得好, 奖励, 最终达到收益/奖励最大化
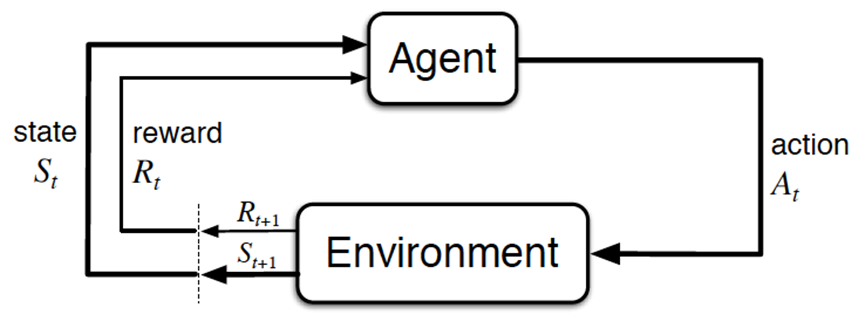
总体而言, agent 依据策略决策从而执行动作 action, 然后通过 environment 从而获取 environment的 state, 最后得到 reward (以便下次再到相同 state时能采取更优的 action), 再按照 “依据策略执行动作-感知状态-得到奖励” 循环进行
RL 与监督学习的区别和 RL 方法的分类
RL 和 监督学习 (supervised learning) 的区别:
- 监督学习的目标是找到一个最优的模型函数, 使其最小化损失函数; RL 只有一系列行为后最终反馈来的 reward, 然后判断当前选择的行为是好是坏. 即 RL 的目标是最大化 agent 策略在和动态 environment 交互过程中的价值, 策略的价值可以等价转换为奖励函数的期望, 即最大化累计下来的奖励期望
- 监督学习在作出错误选择时会立刻反馈给算法, RL 的结果反馈有延时
- 监督学习的输入是独立分布的, 各项数据之间没有关联; RL 面对的输入是在变化的, 算法的行为会影响下一次决策的输入
RL 为得到最优策略从而获取最大化奖励, 有
- 基于值函数的方法: 求解某状态下的值, 寻找最佳的价值函数后, 再提取最佳策略
- 基于策略的方法: 对当前的策略函数估值, 估值后进行策略改进, 不断重复直至策略收敛
马尔科夫决策过程 (Markov decision process, MDP)
前置知识
随机过程: 假设有 个状态, 从一个状态转移到另一个状态, 这样的概率共有 个概率, 可以用一个状态转移矩阵表示
马尔科夫性质: 当且仅当某时刻的状态进取决于上一时刻的状态时, 一个随机过程被称为具有马尔科夫性质
马尔科夫过程: 具有马尔科夫性质的随机过程便是马尔科夫过程
马尔科夫奖励过程: 在马尔科夫过程的基础上加入奖励函数 和折扣因子
- 奖励函数:
马尔科夫决策过程 MDP = 马尔科夫奖励 MRP + 智能体动作因素
根据上文, 在随机过程的基础上
- 增加马尔科夫性质, 即可得到马尔科夫过程
- 再增加奖励, 得到马尔科夫奖励过程 MRP
- 再增加一个来自外界的刺激, 比如智能体的动作, 得到了马尔科夫决策过程 MDP. 通俗讲, MRP 和 MDP 的区别是随波逐流和水手划船的区别
策略学习: 策略梯度, Actor-Criti 到 TRPO, PPO 算法
策略梯度与其突出问题: 采样效率低下
策略梯度的核心算法思想:
- 参数为 的策略 接受状态 , 输出动作概率分布, 在动作概率分布中采样动作, 执行动作, 得到奖励 , 跳到下一个状态
- 使用策略 收集一批样本, 使用梯度下降算法学习样本, 当策略 的参数更新后, 这些样本不能继续使用, 需要重新收集数据
策略函数可以表示为 , 可以理解为一个神经网络, 正常神经网络对损失函数使用梯度下降法求极小值, 优化的对象是神经网络参数 ; 在策略学习中, 是正向传播产生动作, 动作在环境中产生奖励值, 通过奖励值求和产生评价函数, 此时可以针对评价函数做梯度上升.
特定状态下的运动轨迹 可以表示为状态 , 动作 , 奖励值 不断迁移的过程:
某一条轨迹 发生的概率为:
由于每一个轨迹 都有其对应的发生概率, 对所有 出现的概率与其对应的奖励进行加权最后求和, 可得期望值:
上述过程如图所示:
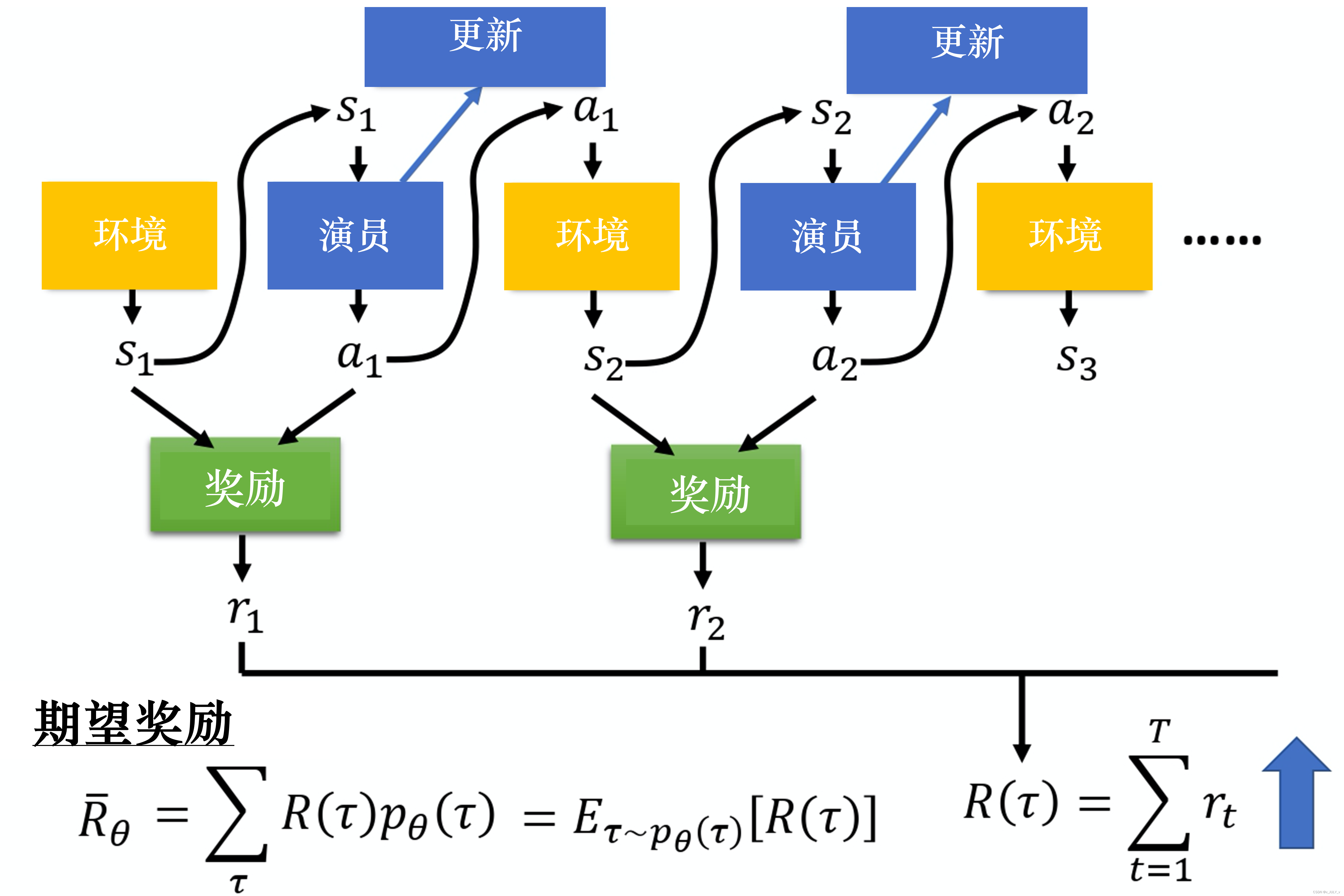
想要奖励越大越好, 可以使用梯度上升来最大化期望奖励. 要进行梯度上升, 先要计算期望奖励 的梯度
策略梯度定理
-
在采样到的数据里, 采样到在某一个状态 要执行一个动作 , 是在整个轨迹 里面的某一个状态和动作的对
-
为了最大化奖励, 假设在 执行 , 最后发现 的奖励是正的, 就要增加在 执行 的概率; 反之减少
-
最后用梯度上升来更新参数
在策略梯度有一个问题, 更新梯度后 , 在对应状态 下采取动作的概率 就不是对应 下的概率了, 之前采样的数据就不能用了. 也即策略梯度的大多数时间都在采样数据
重要性采样:
-
使用另一个策略 与环境交互, 用 采样到的数据去训练
-
假设使用 采样到的数据去训练 , 可以多次使用 采样到的数据, 多次执行梯度上升, 从而多次更新参数
-
需要在 上乘一个重要性权重 , 最终得到
“重要性采样的关键不是说原始分布π(x)未知,所以我们要用p(x)来做样本生成。而是因为相同的样本量,用π(x)分布采样得到的结果方差较大,而用p(x)采样的样本得到的结果方差较小。所以大家困惑重要性权重怎么计算,其实这不是个问题,因为我们是知道π(x)的。”
引入优势演员-评论家算法 (Advantage Actor-Criti): 为避免奖励总为正增加基线
优势函数: 不断鼓励并探索高于平均预期回报的动作从而指导策略更新
采样一条轨迹时可能出现问题:
- 所有动作均为正奖励
- 出现比较大的方差
举个栗子: 某一个状态中可以执行动作 a, b, c, 但是使用蒙特卡洛算法可能只采样到动作 b 或 c, 没有采样到动作 a
- 所有动作的奖励都是正的, 所以 a, b, c 的概率都应该提高
- a 没有被采样到, 所以 a 的概率下降了
- 但问题 a 不一定是一个不好的动作, 它只是没有被采样到
为了解决奖励总为正或方差过大的问题, 需要在梯度计算的公式基础上加一个 baseline , 可以是任意函数, 只要不依赖于动作 即可
的选取:
- 常用轨迹上的奖励均值
优势函数被定义为 , 用于对一个动作在平均意义上比其他动作好多少的度量.
经过到 的推导和一定假设, 得到:

基于信任区域的 TRPO: 加入 KL 散度解决两个分布相差大或步长难以确定的问题
重要性采样还有一个问题: 分布 和 采样足够多次, 得到的期望值是一样的. 但如果采样不够多, 他们方差可能是巨大的. 在公式上即重要性权重远离 1. TRPO (Trust Region Policy Opimization)算法目的是解决这个问题和策略梯度算法中步长难以确定的问题
为了解决 和 相差太大的问题, 加入 KL 散度, 至此采样效率低效的过程通过重要性采样和增加 KL 散度约束解决了
为了解决策略梯度算法中步长难以确定的过程, 考虑在更新时找到一块信任区域, 在这个区域上更新策略时能得到安全性保证.
“总之,TRPO就是考虑到连续动作空间无法每一个动作都搜索一遍,因此大部分情况下只能靠猜。如果要猜,就最好在信任域内部去猜。而TRPO将每一次对策略的更新都限制了信任域内,从而极大地增强了训练的稳定性。”
TRPO的问题在于把 KL 散度约束当作一个额外的约束,没有放在目标里面,导致TRPO很难计算,信任域的计算量太大了
近端策略优化 PPO: 解决 TRPO 计算量大的问题
PPO 算法有两个主要的变种, 近端策略优化惩罚 (PPO-penalty) 和 近端策略优化裁剪 (PPO-clip)
近端策略优化惩罚 PPO-penalty
-
明确目标函数, 优化以下函数使其最大
-
与 TRPO 相似, 使用重要性采样, 并加入 KL 散度
近端策略优化裁剪PPO-clip
也称 PPO2 算法, 转而优化以下函数, 这样做的本质目标是让 和 二者尽可能接近
𝑐𝑙𝑖𝑝 括号里的部分,如果用一句话简要阐述下其核心含义就是:如果 和 之间的概率比落在范围和之外, 将被剪裁,使得其值最小不小于,最大不大于
RLHF
模仿学习 (逆强化学习) 思路下的 RLHF: 从人类反馈中学习
RL 理论上不需要大量标注数据, 实际上它需求的reward存在缺陷
- reward 的制定很困难, 多步决策场景中, 学习器很难获得 reward
- 不好定义什么是好什么是坏
模仿学习的思路是不让模型在人类制定的规则下自己学习, 而是让模型模仿人类的行为. 逆强化学习是其中的一种
逆强化学习没有 reward model, 可以通过人类标注数据训练得到 reward model (相当于有了人类标注数据, 相信它是不错的, 然后可以反推人类因为什么样的奖励函数才会采取这些行为). 有了奖励函数后, 就可以使用一般的强化学习方法去找出最优策略/动作
RLHF: Reinforcement Learning with Human Feedback
-
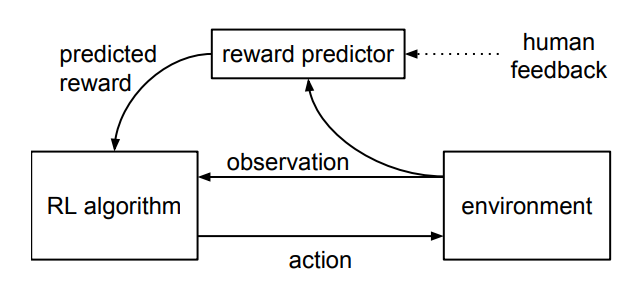
Deep Reinforcement Learning from Human Preferences
- agent 的一对 1-2 秒的行为片段定期地回馈给人类, 人类基于偏好对智能体对智能体的行为作出某种 偏好性的选择评判
- 人类这种基于偏好的选择评判被预测期来预测奖励函数
- 智能体通过预测器预测出的奖励函数作出更优的行为
-
Fine-Tuning Language Models from Human Preferences
-
Reward Model 的训练中, human labelers 给 policy 模型生成的文本进行选择, 这个选择作为 reward model 虚席的标签
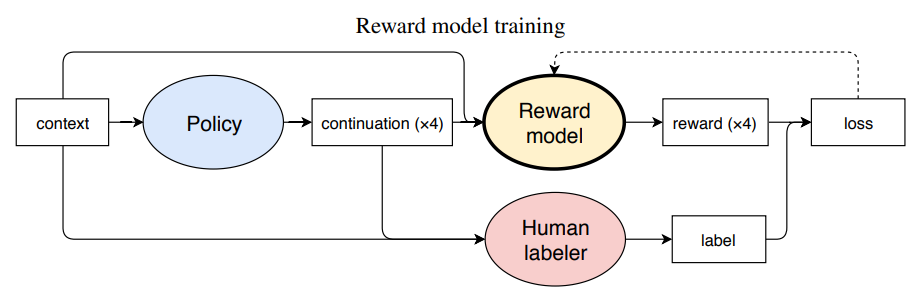
-
reward model 训练好后, 在训练 policy model 时, reward model 可以完全取代 human labelers 选择, 这种基于偏好的选择作为信号传给 policy model, 再使用 PPO 来训练
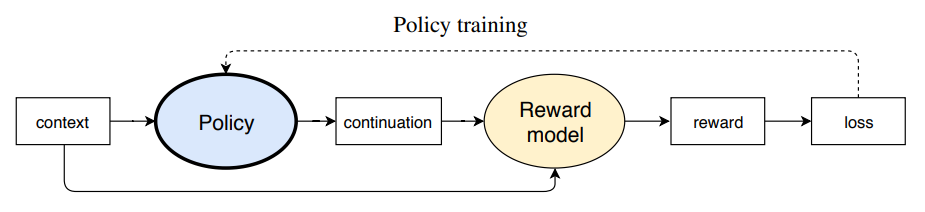
-
-
Learning to summarize with human feedback
这篇文章通过 RLHF 的方式训练语言模型, 让其做摘要任务
- 收集人类对摘要的偏好数据
- 训练 reward model, 使其可以越发准确的判断
- 基于让 reward model 给出的分值最大化的前提, 通过 PPO 算法优化模型策略, 为了避免 reward model 过于绝对, 给 reward model 加了 惩罚项, 防止迭代中的策略与初期的 SFT 策略偏离太远
从 GPT/GPT2/GPT3 到 GPT3.5/GPT4
GPT: 基于 Transformer Decoder 预训练 + 微调/Finetune
NLP 发展中的四种任务处理范式:
- 非神经网络时代的完全监督学习. 手工设计一系列特征模版来输入模型. 模型对任务的处理结果高度依赖于特征模版的设计, 同时也高度依赖领域专家的知识. 如条件随机场 CRF 模型
- 基于神经网络的完全监督学习. 处理范式基本为预训练后的词嵌入表征 + 模型架构的调整. 此时一方面的工作在 word embedding 上, 一部分在模型架构上
- 预训练-微调范式 (Pre-train, Fine-tune). 减少了人工的参与, 不需要对每个任务采取不同的模型架构, 而是在超大的文本数据集上预训练一个具备泛化能力的通用模型, 然后根据下游任务微调即可. 如 GPT1
- 预训练-提示-预测范式 (Pre-train, Prompt, Predict). 如 GPT2, GPT3
GPT = MSA + FFN + 求和与归一化的前置 LN + 残差
(窃以为上面这个标题想准确没准确, 想全面没全面)
GPT 是 OpenAI 在2018年, 通过论文《Improving Language Understanding by Generative Pre-Training》提出的. GPT 即 “Generative Pre-Training Transformer”, 和 BERT 都是 (自监督)预训练-(有监督)微调模型 的典型代表
- 第一阶段, 在未标记的数据上使用语言建模来学习神经网络模型参数
- 针对目标任务使用相应的标记数据来对参数微调 (使用数据量远小于第一阶段)
Decoder 具备文本生成能力, 所以 GPT 选择了 Transformer Decoder only 结构. GPT 删除了 Encoder-Decoder Attention, 只保留了 MSA 和 FFN, 再加上求和与归一化的前置 LN 层与残差
此时层数由 6 -> 12 层, 输入向量维度由原始 Transformer 的 512 维扩大到 768 维, 且将 Attention 的头数从 8 增加到 12.
GPT 训练过程中使用基于最大似然估计的损失函数, 让模型预测的概率分布尽可能接近实际下一个单词的分布.
Self-Attention 和 Masked Self-Attention
还要我教?
需要注意, 点乘就有计算相似度的作用
GPT2 承1启3: 基于 prompt 尝试舍弃微调 直接 zero-shot learning
GPT2 相较于 GPT1 的变动主要体现在两方面上, 一方面是模型结构, 一方面是推理模式
-
模型结构上:
-
LN 被放置在 attention 和 FFN 之前, 称为 pre-norm, 并在最后一层 TransformerBlock 后新增 LN (怀疑是参数里的 post LN)
-
修改初始化的残差层权重, 缩放为原来的, 是残差层的数量. 缩放确保了当 的值相对大时, 残差连接不会对模型产生过大的影响, 从而帮助模型更稳定地训练
-
Embedding 维度由 768 维扩大到 1600 维
-
-
推理模式上:
GPT2 尝试向 zero-shot learning 的方向发展. 此时利用 prompt 实现 zero-shot learning, one-shot learning 和 few-shot learning
GPT3: In-context learning 开启 prompt 新范式 (小样本学习)
GPT3 在 N-shot learning 下的突出能力
最大规模版本的参数达到了1750亿, 层数有96层, 输入维度由12888维, 有96个注意力头. 使用 45T 数据训练
In-Context-Learning (ICL) 的玄机: 隐式微调?
有工作《Rethinking the Role of Demonstrations: What Makes In-Context Learning Work》证明, 少样本提示情况下, ICL 没有从样本中学习. 它发现
- 在提供给 LLM 的样本示例 中, 是否是 的对应正确答案其实并不重要, 随机换成另一个答案 , 这不影响 ICL 效果. ICL 并没学习映射函数
- 对 ICL 影响比较大的是 和 的分布. 输入和输出的分布很重要
也有一些工作认为 LLM 通过给出的示例隐式的学习了映射函数
- 比如《What learning algorithm is in-context learning? Investigations with linear models》认为激活函数中包含了一些简单的映射函数, LLM 通过示例能激发对应的那一个
- 比如《Why Can GPT Learn In-Context? Language Models Secretly Perform Gradient Descent as Meta-Optimizers》将 ICL 看作一种隐式的 Fine-tuning, LLM 中的注意力层在推理过程中实现了一个隐式的参数优化过程
Prompt 技术的升级与创新: 指令微调技术 (IFT) 和思维链技术 (CoT)
Google 提出 FLAN 大模型: 基于指令微调技术 Instruction Fine-Tuning (IFT)
FLAN (Finetuned Language Models Are Zero-Shot Learners), 提出了指令微调, 极大地提高了 zero-shot 能力
指令微调的数据通常是由人工手写指令和语言模型引导的指令实例的集合, 这些指令数据由三个主要部分组成: 指令, 输入, 输出. 对于给定的指令, 可以有多个输入输出实例
相较于GPT-3, 区别在于 finetune, FLAN 的核心思想是: 面对给定的任务 A 时, 首先讲模型在大量的其他不同类型任务比如 BCD 上微调, 微调的方式是将任务的指令与数据进行拼接 (可以理解为一种 Prompt), 随后给出任务 A 的指令, 直接进行推断

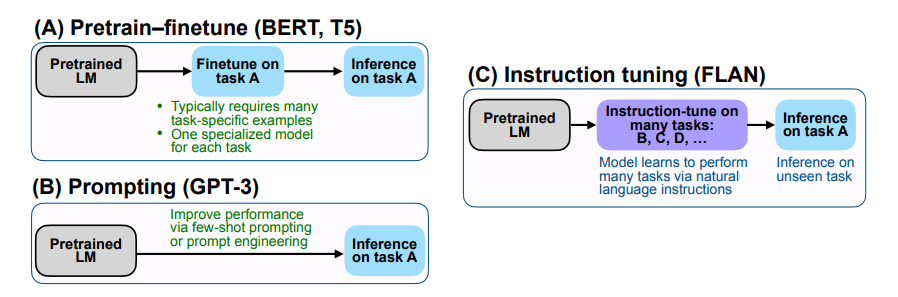
相当于通过指令微调后, 模型可以更好的做之前与训练时没见过的新任务, 且降低了对 prompt 的敏感度
关于 prompt learning 的理解
prompt learning 最简单的理解就是逐步学会人类的各种自然指令, 而不用根据虾油任务去微调模型或更改模型参数
-
GPT3 出来之前(2020年之前),模型基本都是预训练 + 微调,比如GPT1和BERT
-
GPT3刚出来的时候,可以只预训练 不微调,让模型直接学习人类指令直接干活 即prompt learning,之所以可以做到如此 是因为GPT3 当时具备了零样本或少样本学习能力
当然,说是说只预训练 不微调,我个人觉得还是微调了的,只是如上文所说的某种隐式微调而已 -
2021年,Google发现微调下GPT3后 比OpenAI不微调GPT3在零样本上的学习能力更加强大
从而现在又重新回归:预训练之后 再根据下游任务微调的模式,最后封装给用户,客户去prompt模型
基于思维链 (Chain-of-thought) 技术下的 prompt
“let’s think step by step !”
GPT3到GPT3.5: 从 InstructGPT 到 ChatGPT 初版的迭代过程
基于 GPT3 的发展路线: 一条侧重代码/推理的 Codex, 一条侧重理解人类的 InstructGPT
-
第一条线: 为了具备代码/推理能力: GPT3 + 代码训练 = Codex
2020年 OpenAI 发布了 GPT3 的论文《Language Models are Few-Shot Learners》, 2021.07 发布Codex 的论文《Evaluating Large Language Models Trained on Code》
-
第二条线: 为了理解人类: GPT3 + 指令学习 + RLHF = InstructGPT
基于 GPT-3.5 的发展路线: 增强代码/推理能力且更懂人类, 迭代出 ChatGPT
- 首先, 融合代码/推理与理解人类的能力, 基于 code-cushman-oo2 迭代出 text-davinci-002
- 其次, 为了进一步理解人类, text-davinci-002 + RLHF = text-davinci-003/ChatGPT
ChatGPT 初版与 InstructGPT 的差别
基于 GPT3 还是 GPT3.5?
- InstructGPT 是在 GPT-3 上 finetune
- ChatGPT 是在 GPT-3.5 上 finetune
基于 GPT4 的 ChatGPT 改进版: 新增多模态技术能力
- GPT-4 的上下文长度为 8192 tokens, 也有 32768 tokens 版本
- GPT-4 经过预训练后, 再通过 RLHF 的方法微调
- RLHF 之外, 为了让模型输出安全的回答, 过程中还提出了基于规则的奖励模型 RBRMs (rule-based reward models), 奖励规则由人编写, 相当于是零样本下的 GPT-4 的决策依据或分类器
- 经过测试, GPT-4 在遵循人类指令上表现的更好
- 具备了多模态能力, 可以接受图片形式的输入
- GPT-4 的训练方式与 ChatGPT 初版或 InstructGPT 一样
- 先收集数据. 人工标注问题-答案对, 基于人类偏好对模型输出的多个答案进行排序的答案
- 通过人工标注的数据 (问题-答案对) 监督微调 GPT-4
- 通过对模型多个回答进行人工排序的数据训练奖励模型
- 最大化奖励函数的前提下, 通过 PPO 算法继续微调 GPT-4 模型
InstructGPT/ChatGPT 训练三阶段及多轮对话能力
基于 GPT3 的 InstructGPT 训练三阶段
InstructGPT: 基于 RLHF 微调的 GPT
InstructGPT 的训练分为三个阶段: 1. 有监督微调"经过自监督预训练好的GPT3"; 2. 基于人类偏好排序的数据训练一个奖励模型; 3. 在最大化奖励的目标下通过 PPO 算法来优化策略
-
阶段1: 利用人类问答数据对 GPT3 进行有监督训练出 SFT 模型 (作为baseline)
这个微调好的 GPT-3 我们称之为 SFT(Supervised fine-tune) 模型, 它作为 baseline 具备了最基本的预测能力
-
阶段2: 通过 RLHF 训练一个奖励模型 reward model
使用阶段1得到的 SFT 模型作为 RM 模型, 回答数据集的问题, 生成多个答案, 人工对答案的好坏进行标注并排序, 排序结果用来训练一个奖励模型 RM, 具体做法是学习排序结果从而理解人类的偏好
-
阶段3: 通过训练好的 RM 模型预测结果且通过 PPO 算法优化模型策略
第一阶段微调好的 SFT 模型初始化一个 PPO 模型; 让 PPO 模型回答一些未标注的新问题, 让阶段2训练好的奖励模型 RM 去给 PPO 模型的预测结果打分并排序; 最大化奖励, 优化 PPO 模型的生成策略, 策略优化的过程中使用 PPO 算法限制策略更新范围; 重复直至策略最优
所有模型使用 Adam 优化七训练, , , 这三步的代价比预训练 GPT3 要小很多
InstructGPT 训练阶段1: 针对预训练后的 GPT3 进行监督微调
阶段1使用监督学习方法对 GPT-3 模型进行微调, 使用 labeler demonstrations 作为训练数据. 微调过程中:
- 进行 16 epochs 训练
- 余弦学习率衰减策略
- 残差丢弃率 (residual dropout) 为 0.2
InstructGPT 训练阶段2: 如何对多个输出排序及如何训练 RM 模型
训练 RM 的核心是由人类对 SFT 生成的多个输出 (基于同一个输入) 进行排序, 再用来训练 RM——直观的理解是, RM 需要模仿人类对回答语句的排序思路
-
SFT 生成了 ABCD 四个回答语句, 人类对照着 Prompt 输入来对四个回答的好坏做出合适的排序, 如 D>C>A=B
-
四个语句两两组合分别计算 loss 再相加取平均, 即计算 个 loss, loss 形式如下:
把问题 和答案 放进奖励函数 中, 再把问题 和 也放进奖励函数 中, 然后分别输出, 假定 比 排序更高, 所以二者作排序损失函数(Pairwise ranking loss), 奖励的差异表示一种应答比另一种应答更受人类标注者青睐的对数概率, 希望相减的结果越大越好
本质上是最小化
-
训练集上训练了一个 epoch, lr=9e-6, 采用余弦学习率调度策略, 训练结束时学习率降低至初始值的 10%
InstructGPT 训练阶段3: 如何通过 PPO 算法进一步优化模型的策略
具体解读可看原博客, 很详细; 粗略的只需理解:
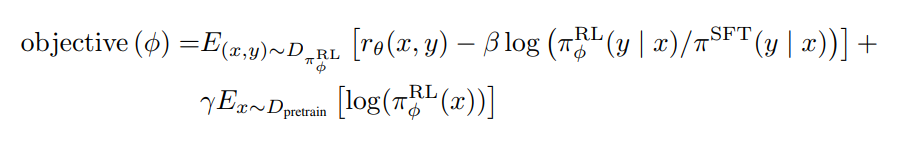
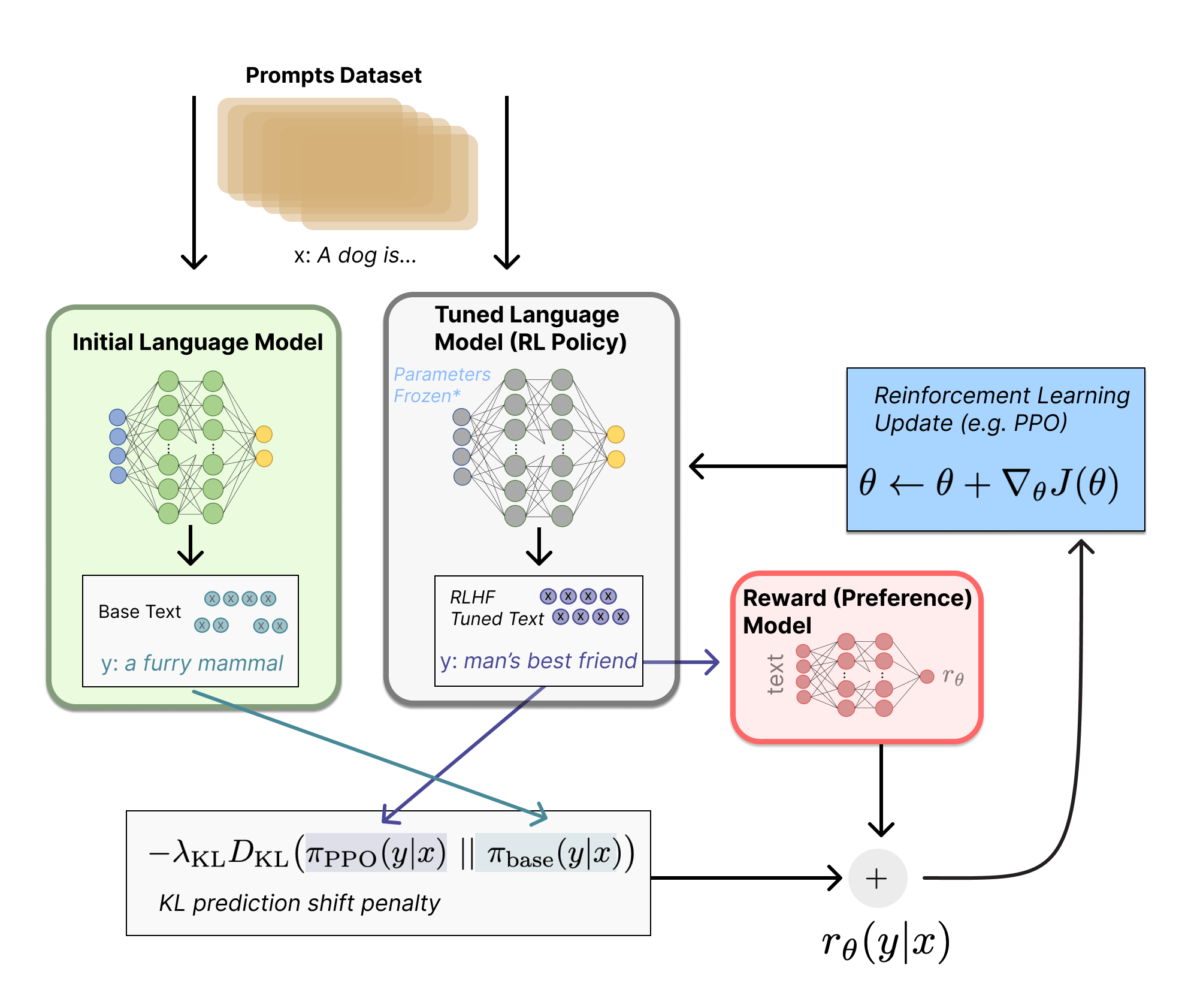
如何通过 ColossalChat 架构图和微软 DeepSpeed Chat 的实现更好的理解 PPO 迭代过程
pass
DPO 原理解析: 从 RLHF, Claude 的 RAILF 到 DPO, Zephyr
从 Anthropic 的 RLHF 到 Claude 的 RAILF
Anthropic 的 LLM 论文: 如何通过 RLHF 训练一个有用且无害的 AI 助手
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
本篇文章中的训练模式为:
- 上下文蒸馏出一个语言模型 (没做 SFT, 只做了一定的 prompt engineer), 初始化一个 preference model 和一个 policy model
- 偏好模型在人类反馈的数据下做微调, 得到最终的偏好模型
- 策略模型在偏好模型的指引下, 迭代策略
- 最后在线更新偏好模型, 再之后继续迭代策略模型
偏好模型的训练: 从基础模型到 PM 预训练, 人类反馈微调
ahthropic LLM 与 instructGPT 工作的对比:
- InstructGPT 不包括无害训练, 训练偏好模型没有超过 6B, ahthropic有 13M 到 52B 的偏好模型
- InstructGPT 在 RLHF 迭代策略时, 将预训练的数据拉回来做了混合, 避免评估性能的下降, 但是 ahthropic 没有这个操作
- ahthropic 的工作与 InstructGPT/LaMDA 等更大的区别是, ahthropic 探索偏好模型的 "在线"训练模式, 即会保持更新与工作者互动的偏好模型, 以逐步获得更高质量的数据
通过 RLHF 继续迭代策略: 在保持更新的偏好模型的指引下
ahthropic 会定期更新他们的偏好模型, 在保持更新的偏好模型的指引下, 最终的 RLHF 的效果更好
Claude 及与 ChatGPT 的异同
Constitutional AI: Harmlessness from AI Feedback
Claude 与 ChatGPT 最大的不同在于:
- ChatGPT 用人类偏好训练 RM 再 RL (即 RLHF)
- Claude 基于 AI 偏好模型训练 RM 再 RL (即 RLAIF)
Claude 在 RL 阶段从阶段一的 STF 模型中采样一个模型来评估两个 response 中哪一个更好, 然后从这个 AI 偏好数据集中训练一个偏好模型, 然后我们使用偏好模型作为奖励信号进行 RL 训练, 即使用"来自 AI 反馈的 RL" (RLAIF)
Claude 为何采用 RAIHF 而非 RLHF?
- RLHF 的奖励信号实际上来自人类偏好训练出来的 AI 偏好模型 (PM), 而不是直接来自人类监督
- 之前 RLHF 训练出的模型经常拒绝一些有争议但实际上对专业人士很有帮助的问题, 比如生产香烟, 不能做出高情商的婉拒
- RLHF 训练中自动化程度不够高
Claude 两阶段训练方式: 先监督微调, 后 RAIHF
监督微调阶段
首先使用 AI 模型生成对无害问题的回答, 这些回答最开始都是有问题的, 然后我们要求模型根据 constitution 中的一项原则对回答进行批判, 然后根据批判对原始回答进行修正; 按顺序反复修改回答, 之后对最终修订的回答进行监督学习, 微调一个预训练的语言模型
RL 阶段
使用监督微调阶段得到的模型对 prompt 生成多个 response, 将 prompt-response 对视为无害偏好数据集, 将其与人类偏好数据集混合在一起; 在这些数据上训练一个偏好模型 PM; 最后通过 RL 对在 PM 指导下的阶段一的模型进行微调, 得到 RLAIF 训练后的模型
偏好优化 DPO
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
DPO 与 RLHF 的本质区别
-
做 SFT 后, RLHF 将奖励模型拟合到人类偏好数据集上, 然后通过 RL 方法如 PPO 算法优化语言模型的策略. 即经典的 ChatGPT 三阶段训练方式
- supervised fine-tuning (SFT)
- preference sampling and reward learning
- reinforcement-learning optimization
RLHF 远比监督学习复杂得多, 计算成本大
-
DPO 通过简单的分类目标直接优化最满足偏好的策略, 而没有明确的奖励函数或 RL
具体而言, DPO 本质在于增加了被首选的 response 相对不被首选的 response 的对数概率, 但它包含了一个动态的, 每个示例的重要性权重, 以防概率比让模型能力退化. DPO 依赖于理论片好魔性, 衡量给定的奖励函数与经验偏好数据的一致性
DPO 的逐步推导
带 KL 约束奖励的最大化目标的推导
由上面三个公式可以得到:
“推导出奖励函数 和策略 𝜋 的联系,就是为了把公式 2 所示的 ranking loss 中的 换掉,从而也就完美实现了 DPO 的目标:根本就不需要训练奖励函数”
求解 DPO 目标函数梯度的推导
pass
Zephyr 7B: 基于 Mistral 7B 微调且采取 AIF + DPO
三步骤训练方式: SFT + AIF + DPO (与ChatGPT 的三阶段训练方式有着本质区别, Zephyr 的三步骤训练方式中的步骤二只是 AI 标注数据, 不涉及奖励模型的训练)
-
通过大规模, 自指导式数据集 (UltraChat) 做精炼的监督微调 (dSFT)
-
通过集成收集 AI 反馈 (AIF) 聊天模型完成情况, 然后通过 GPT-4(UltraFeedback) 进行评分并二值化为偏好
ChatGPT 是对同一个 prompt 采样同一个模型, 针对该 prompt 的多个答案人工排序; Zephyr 是针对同一个 prompt, 采样多个模型针对该 prompt 的各自答案, 然后 AI 来排序
-
利用反馈数据对 dSFT 模型进行直接偏好优化 (DPO)