多模态MLLM(Multimodal-Large-Language Models)
多模态的两个挑战:
- 数据对齐: 视觉和文本数据间的正确对齐
- 复杂性: 模型架构和训练过程的复杂性
实现路径:
- 模态融合
- 早期融合: 简单地连接特征或将两种模式嵌入到模型早期的共享空间中
- 中间融合: 每种模态独立处理后进行融合, 一般允许每个模态在集成前通过跨模态注意力机制形成中间理解
- 后期/决策级融合: 两种模态经过深层独立处理后, 在输出附近进行融合. 可以保持模态更长时间的分离, 允许在集成前进行更专业的处理
- 模态对齐
- 跨模态注意力: 常使用Transformer将模态的一种元素与另一种模态的元素对齐. 如图像中的对象与句子中的单词对齐
- 联合嵌入空间: 创造共享表示空间. 如CLIP
- 培训策略
- 对比学习. 常用于对齐, 涉及到训练模型使得相似的文本和图像的表示更加接近, 如CLIP的协方差矩阵对角元素值最大, 其他的值更小.
- 多任务学习
MLLM的常用技术和架构
常见技术与架构
1. CLIP, 对比语言-图像预训练
- 架构:使用文本Transformer和图像 ResNet/ViT。
- 融合策略:后期融合,重点是学习联合嵌入空间。
- 对齐方法:使用对比学习进行训练,其中图像-文本对在共享嵌入空间中对齐。
2. DALL-E
- 架构:基于 GPT-3 架构,适用于处理文本和图像标记。
- 融合策略:早期到中期融合,其中文本和图像特征以交织的方式进行处理。
- 对齐方法:使用自回归模型,以顺序方式理解文本和图像特征。
3. VisualBERT
- 架构:类似 BERT 的模型,可处理视觉和文本信息。
- 融合策略:与跨模式注意机制的中间融合。
- 对齐方法:在变压器框架内使用注意力对齐文本和图像特征。
4. LXMERT (Learning Cross-Modality Encoder Representations from Transformers):
- 架构:使用单独的语言和视觉编码器,然后是跨模态编码器。
- 融合策略:使用专用的跨模态编码器进行中间融合。
- 对齐方法:在语言和视觉编码器之间采用跨模式注意力。
代表性项目
1. GPT4V
2. LLaVA
爱来自微软, Visual Instruction Tuning, LLaVA是对LLaMA的改进.
LLaMA: Open and Efficient Foundation Language Models
motivation: Hoffmann的缩放定律: 给定计算预算, 最佳性能由更多数据训练的较小模型实现, 而非最大的模型. 来自Scaling Laws for Neural Language Models, 也称大模型的缩放定律
LLaMA是开源的, 所用数据集均为公开可得的数据集. 技术要点有:
- 基于xformers的Causal-MSA.
- 位置编码 --> 旋转编码(RoPE)
- LayerNorm --> RMSNorm
- GeLU --> SwiGLU
LLaVa
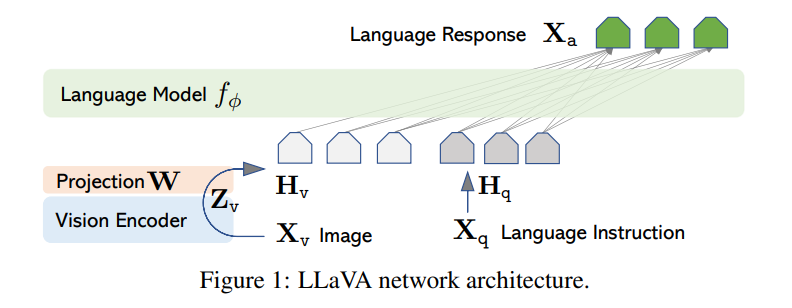
结构:
Vision Encoder来自预训练的CLIP的ViT-L/14, 经过编码器和投影后得到, 图片的处理方式考虑到了轻量级, 成本低的特点
训练:
- 特征对齐Pre-training. 在图像-文本对只有投影矩阵是需要更新的
- Fine-tuning End-to-End. End-to-End端到端的学习: 特征提取的任务也交给模型去做, 直接输入原始数据. 这里使用Visual Chat和Science QA两个数据集训练. 仅保持CLIP冻结
测试:
使用数据集通过GPT-4生成, 数据集里包括30张图片的caption和目标检测信息, 每张图片对应三个问题, 共90个样本.
作者本人认为LLaVA取得的效果来自data quality. 这里数据集构建的一个创新点在于使用GPT4构造language-image instruction数据集.
CLIP(Contrastive Language-Image Pre-training)
爱来自OpenAI, 用于结合图像和文本的多模态模型. CLIP是用文本作为来训练可迁移的视觉模型, 同时期的DALL-E是基于文本生成
LLM和MLLM的差异
-
输入方式
VLM输入视觉图像和文本, LLM只处理和生成文本
-
任务多功能性
VLM要完成理解和关联视觉和文本数据中的信息的任务, LLM专门从事仅涉及文本的任务
-
集成的复杂性
VLM设计两种模态, 更复杂
综述A Survey on Multimodal Large Language Models
来自中科大和腾讯, [github仓库](BradyFU/Awesome-Multimodal-Large-Language-Models: :sparkles::sparkles:Latest Papers and Datasets on Multimodal Large Language Models, and Their Evaluation. (github.com))
MLLM的三个关键技术和一个应用
- 指令微调Multimodal Instruction Tuning, M-IT
- 上下文学习Multimodal In-Context Learning, M-ICL
- 思维链Multimodal Chain of Thought, M-CoT
- LLM辅助的视觉推理LLM-Aided Visual Reasoning, LAVR
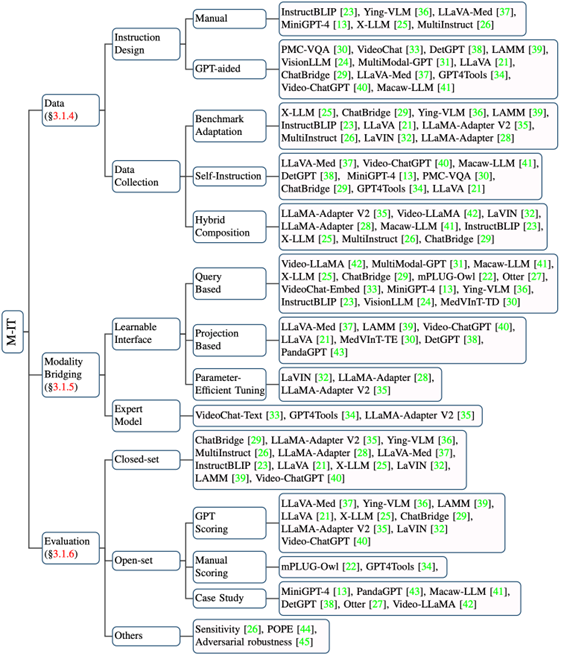
指令微调M-IT
Instruction, 指对任务的描述, M-IT是一种通过指令格式的数据来微调预训练MLLM的技术

多模态指令数据的基本形式
上下文学习M-ICL
In-Context-Learning指给定少量样例作为Prompt输入, 激发模型潜在能力并规范化模型的输出

这方面的研究工作相对较少, 以Flamingo为代表
MLLM的ICL能力比较依赖训练, 目前仍缺乏对样例选择和样例顺序等方面的深入研究
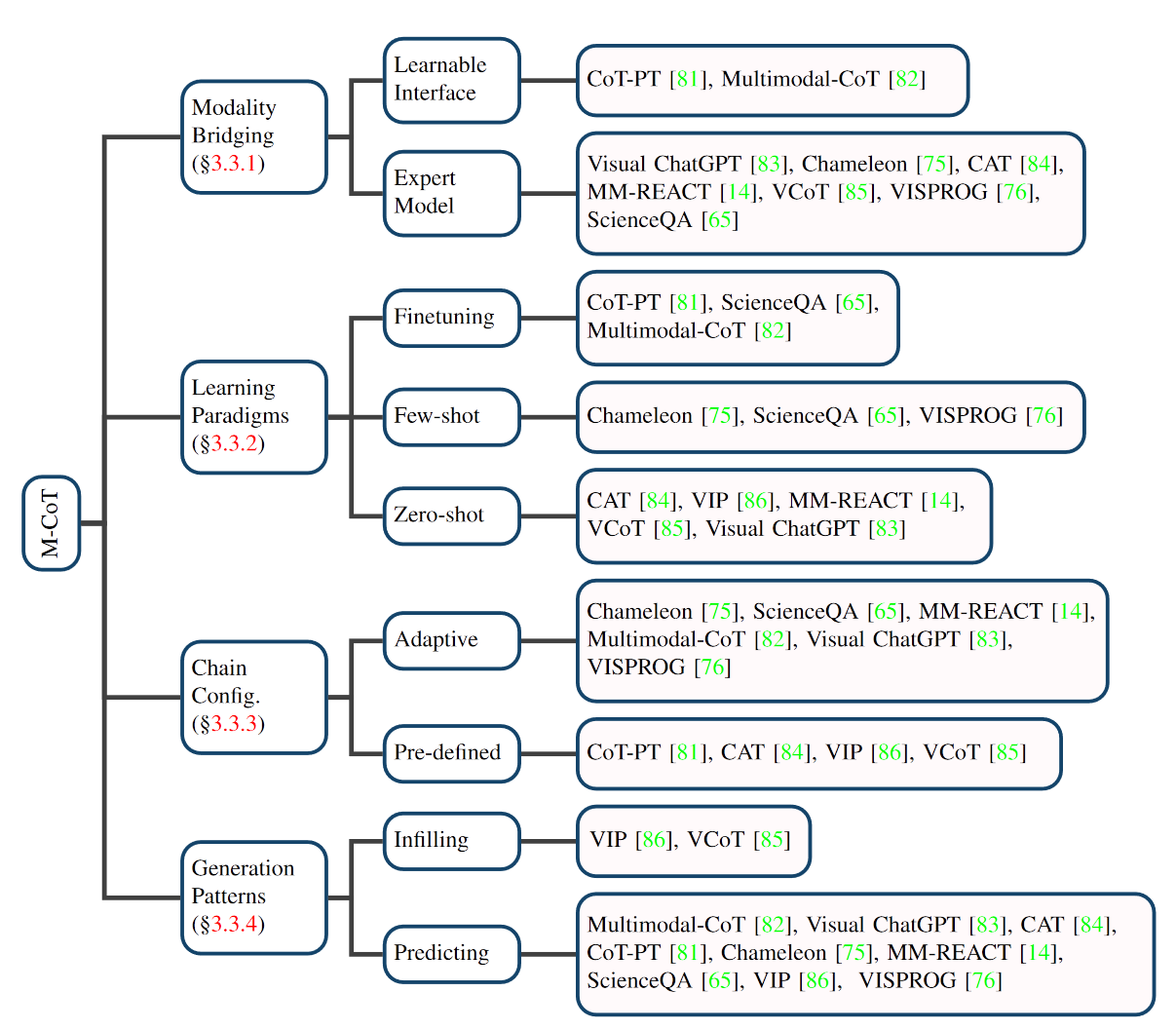
多模态思维链M-CoT
从模态桥接, 学习范式, 思维链配置和生成模式四个方面总结:
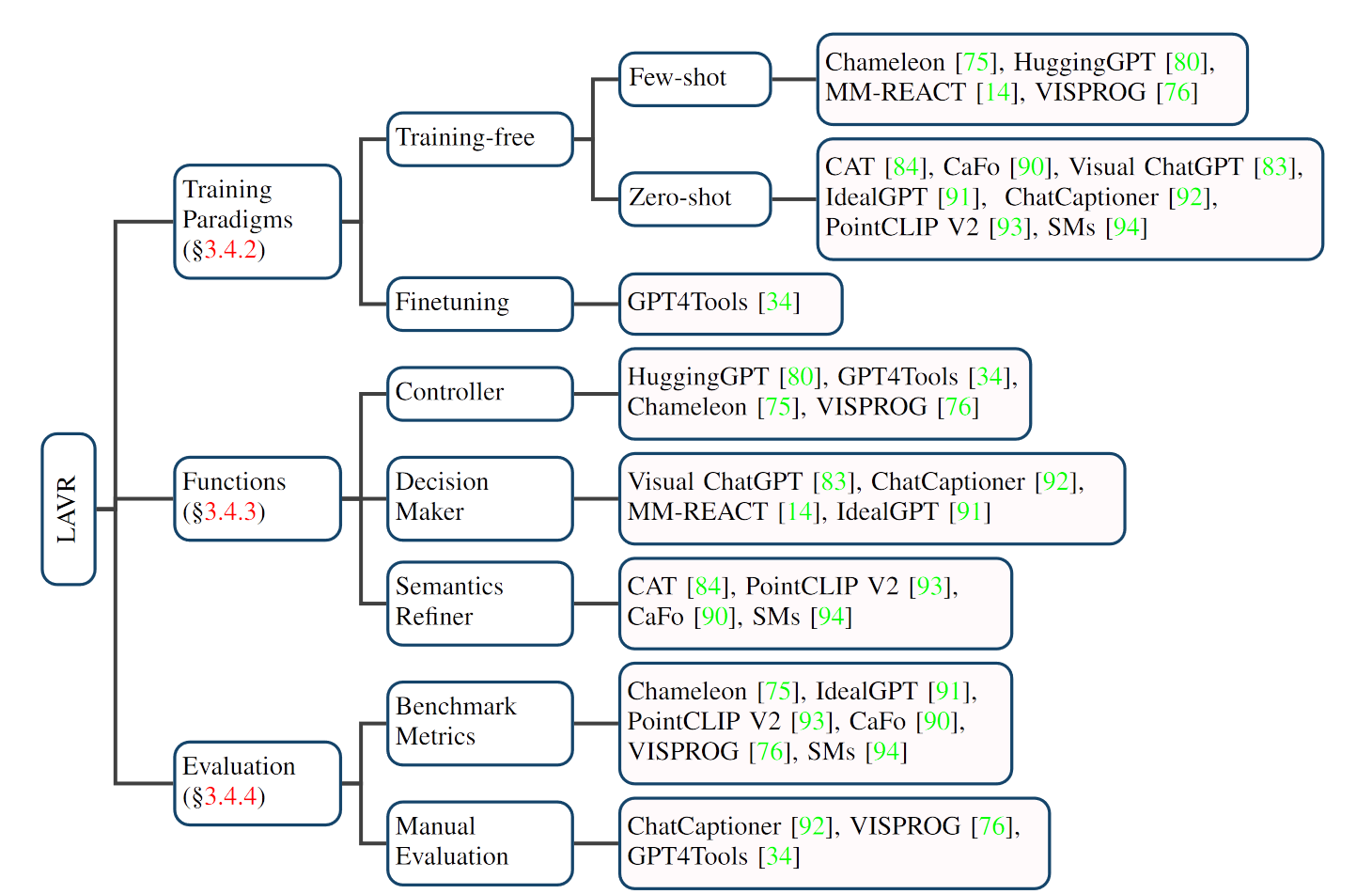
LLM辅助的视觉推理LAVR
特点
- 强大的zero/few-shot泛化能力
- 涌现能力
- 更好的互动性和可控性
从训练范式, LLM扮演的角色和评测三个部分总结
挑战和未来方向
MLLM存在的问题
- MLLM感知能力受限. 视觉信息获取有限, 信息容量和计算负担间有妥协
- MLLM的推理链脆弱. 简单的多模态推理问题也可能有错误
- MLLM的指令服从能力有待提高. 指令微调后, 简单地指令仍无法输出预期答案
- 物体幻视问题. MLLM可能编造物体
- 高效参数训练. MLLM模型容量较大
文章总结
1. Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs
motivation: 视觉方面, 模型往往只基于实例级别的对比语言-图像预训练(CLIP), CLIP的embedding中识别不准确主要来源于那些视觉上不同但编码相似的图像. 在特殊场景上, 不如随机猜测
method: 某些系统性的视觉模式容易产生误解. 参考MMVP基准测试中的问题和选项, 将这些视觉模式转换为语言描述. 容易产生误解的九种视觉模式如下:
- 朝向和方向
- 某个特征是否出现
- 某种状态或条件
- 数量的问题
- 颜色和外观
- 位置和上下文
- 结构特征
- 文字
- 不同的视角
引入新基准MMVP-VLM, 将MMVP基准测试中的问题子集提炼成语言描述, 分类为视觉模式, 使每个视觉模式由15个文本-图像对表示
过去有关CLIP在MVP基准测试的研究表明, 扩大CLIP规模无助于解决视觉模式问题, 仅在"颜色和外观"与"状态和条件"两种视觉模式上有帮助. 实验表明, CLIP在特定视觉模式上表现不佳时, MLLM也会显示出相似的不足.
全新特征混合(MoF)方法
MoF方法将视觉的自监督学习特征(DINOv2)和CLIP特征结合在一起, 在LLaVA上实验
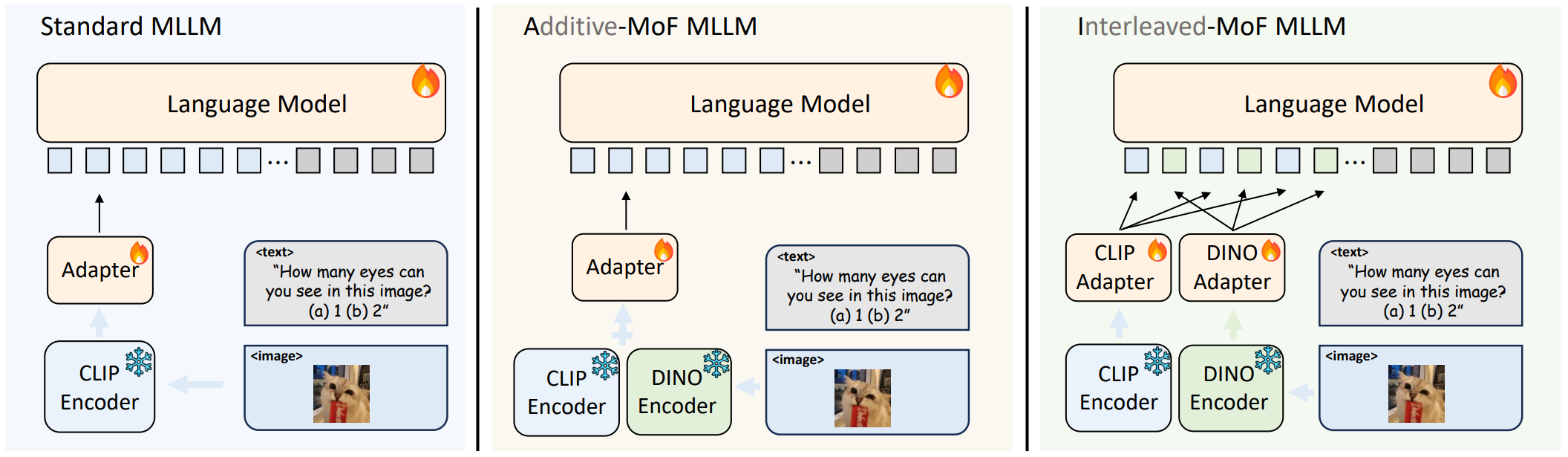
- 标准MLLM使用既有CLIP预训练视觉编码器
- 加性特征混合(A-MoF MLLM)大语言模型. Adapter前CLIP和DINOv2特征进行线性混合
- 交错特征混合(I-MoF MLLM)大语言模型. Adapter后CLIP视觉token和DINOv2视觉token进行空间交错
两种方法只依赖视觉的自监督学习特征, 提升了视觉识别能力, 但削弱了语言处理性能
结论:
- 自监督学习特征A-MoF
- DINOv2特征比例提高, LM在执行指令方面的能力下降
- DINOv2特征比例的增加提升了模型对视觉信息的理解能力, 75%为拐点
- 交错特征混合I-MoF
- 执行指令的能力不会受到影响
- 对视觉信息的理解有大幅提升
2. VILA: On Pre-training for Visual Language Models
motivation and method
MLLMs的框架分为两类
-
基于交叉注意力, 如Flamingo, BLIP-2
-
基于自回归, 视觉和文本tokens拼接到一起作为输入, 如Fuyu, PaLM-E, LLaVA
自回归MLLMs包括Visual Encoder(VE), LLM和连接两个模态的Projector, Projector可以是Linear(LLaVA)或TransfomerBlock(InstructBLIP, OpenFlamingo)
- Step0: Project init. 图片-文本对训练projector, 如InsructBlip, BLIP-2, LLaVA
- Step1: Interleaved pre-training(Visual Language Pre-training). 图文交织训练LLM和projector, 固定CLIP
- Step2: Vision-text SFT(Visual Instruction-tuning). 视觉指令微调, 训练LLM和projector
Visual Language Pre-training的研究
- prompt-tuning. 只训projector, 防止纯文本训练的LLM能力退化
- fine-tuning: 训projector和LLM
结论看出, 容量更大的TransformerBlock作为project, LLM微调的收益更明显, 只训projector性能很差; 容量较小的linear作为project, 只训projector能得到更好的效果. Step1预训练期间冻结LLM会导致few-shot性能变差, 也即会影响泛化性. ---- 调整LLM会为视觉和文本的embedding提供更好的对齐, 证据如下
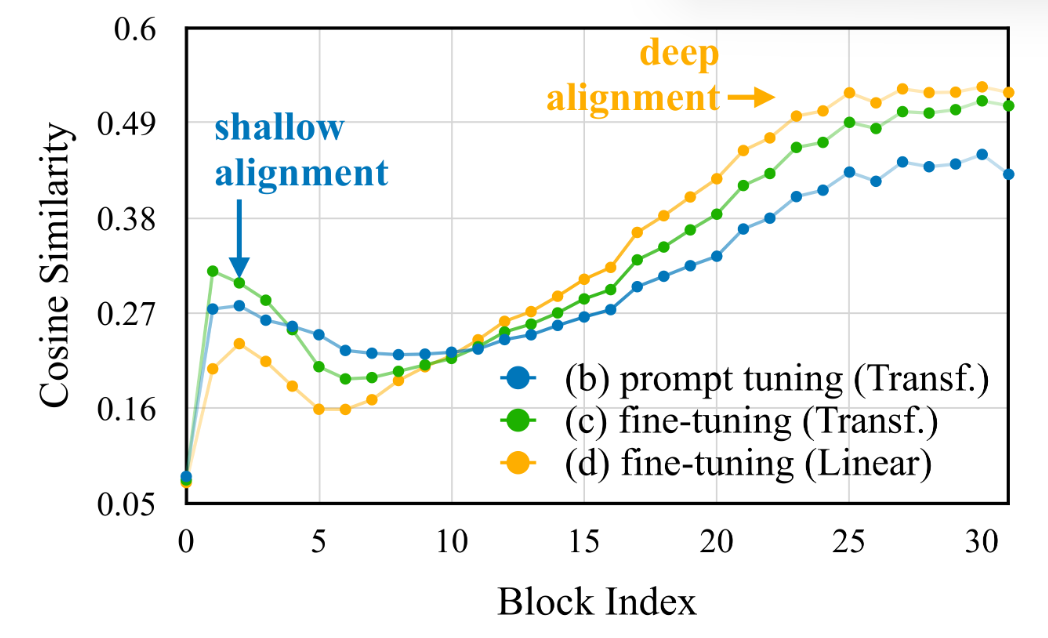
图文交织数据很重要
- 图文样本对数据. 图片和文本一一对应, 如COYO
- 图文交织数据. 任意交错的图像和文本序列
1 | {'image_info': [{'face_detections': None, |
指令微调可以恢复LLM能力
图文交织数据缓解了LLM能力的退化,但仍有5.3%的gap。一种直观的办法是在训练时混合用于训练LLM的纯文本数据,但这种数据通常是私有的,且如何配比来配合图文交织数据仍不明确。
幸运的是,LLM的纯文本能力可能只是暂时被隐藏,并没有被遗忘。在SFT期间添加纯文本数据可以弥补退化,尽管与文本预训练语料库(通常是万亿规模)相比,使用的规模要小得多
conclusion
- 预训练期间freeze掉LLM可以取得不错的zero-shot效果, 但缺乏上下文能力(few-shot能力差)
- 图文交织数据比图片-文本对数据效果好
- 指令微调可以恢复LLM的能力
3. BenchLMM: Benchmarking Cross-style Visual Capability of Large Multimodal Models
motivation
BenchLMM 测试集专为评估大型多模态模型在处理不同视觉风格时的能力而设计, 包括艺术风格, 传感器风格和应用风格三个维度
- 艺术风格: 多种独特的视觉表达形式, 如卡通, 绘画, 纹身. VLM不能解释创意元素或风格特点
- 传感器风格: 不同的成像技术, 如红外成像, X光扫描和CT图像. VLM不能解读特殊成像技术产生的视觉差异
- 应用风格: 一些特定的实际应用场景, 如遥感图像分析, 自动驾驶中的视觉识别, 机器人视觉系统. VLM不能适应特定领域的视觉特征和需求
method and conclusion
风格提示增强Style Prompt Enhancement(简称SPE). 模型自行判断图像风格, 再进行问题解答, 这一过程不需要对模型进行额外的训练或改造, 利用模型本身提升其在多样化视觉环境中的表现.
模型的错误反思能力. 如GPT-4V能识别并解释其错误答案的原因, 还能在错误反思过程中提供详细的推理链条
4. Prompting Large Vision-Language Models for Compositional Reasoning
motivation
CLIP是图像和文本在embedding上对齐, 在视觉语言组合性上具有局限性, 探究原因如下:
- 复杂多模态数据使用单一向量表示
- 基于embedding的方法缺乏逐步推理
method: KEYCOMP提示大型视觉语言模型描述图像并进行组合推理
- 从文本中自动检测出一组关键词K, 以指导VLM描述图像的相关内容
- 使用预训练的VLM为图像生成文本描述. 通过使用关键词K来引导图像描述的生成, 以确保VLM专注于图像细节, 以便于图像-文本匹配
- LLM推理与解释. 鉴于LLM展示出令人印象深刻的zero-shot推理能力,我们提示LLM对生成的图像描述和给定的字幕进行推理,并为Winoground任务选择答案。
5. CoCoT: Contrastive Chain-of-Thought Prompting for Large Multimodal Models with Multiple Image Inputs
motivation
在多图像输入时的问题:
- 缺乏细粒度感知. LM处理视觉内容会丢失图像细节
- 跨多图像信息融合困难. LMMs难以理解图像间的关系和互动, 语言描述图像内和图像间关系很复杂
method: Contrastive Chain-of-Thought, CoCoT
引导LMMs比较多图像输入间的相似性和差异性, 基于相似性和差异性回答问题