AI 绘图笔记
资源下载
WebUI 资源整合包
按照b站视频教程进行下载, 已经更新到 v4.7
代理设置
我选择使用代理暴力下载所有资源, 不使用国内镜像, 在设置中进行具体操作. 如果使用 Clash, 代理端口默认是 7890. 勾选所有 “将代理应用到xxx”, 取消勾选 “PyPI国内镜像”, “Git国内镜像”, “HuggingFace国内镜像”, “替换扩展列表链接”.
插件安装
由于蓝桥杯的视频教程中用到了 roop 插件, 这里以 roop 为例进行安装.
roop 下载
感谢前人的馈赠
- 将 repo 克隆到 extensions 文件夹中
- 在整合包的 “高级选项-环境维护-重装单个 Python 组件” 中安装 ifnude 包 (只需输入安装包名称即可)
- 根据教程, 如果有 Nonetype 的一个有关驱动的问题, 需要下载一个 onnx 文件并替换. 这里我没有这个问题,
魔法导论笔记来源
文生图
设置
Tag
常用正向 Tag: masterpiece, best quality
常用反向 Tag: lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry
如果你不知道那些 Tag 好,可以使用标签超市
进阶用法, 以 girl 这个 Tag 作为例子
- (girl) 加权重,这里是1.1倍。括号是可以叠加的,如((girl)) 加很多权重。1.1*1.1=1.21倍
- [girl] 减权重,一般用的少。减权重也一般就用下面的指定倍数。
- (girl:1.5) 指定倍数,这里是1.5倍的权重。还可以 (girl:0.9) 达到减权重的效果
CFG
分类器自由指导 Classifier-Free Guidance (CFG) 控制了 txt2img 和 img2img 中遵循 prompt 的程度. CFG 越大自由度越大, CFG 越小越严格遵循输入文本提示
放大图片
AI 基本上无法生成超级大图,想要生成高清图片正确的做法是分辨率调小, 比如 512x768, 然后开启 “高清修复”. 作者的推荐
图生图
可以全部修改, 部分修改, 指定颜色修改
查询图片参数
AI 生成图片会自动保存全部参数到原图中, 在WebUI的 “图片信息” 一栏可通过解析原图看到
ControlNet 精细控制画面
预训练 + 模型介绍
ControlNet 对文生图可以控制人物姿势/深度/线稿上色控制
预处理器 + 模型
-
None, 有骨骼图
-
canny + control_canny模型, 边缘检测, 达到上色效果. 可以使用 lineart 和 lineart_anime 替换原来的 canny 模型

-
depth + control_depth模型, 深度图, 达到指定画面结构. 新版本可以用Leres++ 或 Zoe 预处理器, 再使用 Depth 模型

-
hed + contorl_head模型, 没有 canny 那么精准的控制, AI自由发挥更多

-
OpenPose+control_openpose模型, 人体动作控制

-
MLSD 线段图

-
Scribble 手绘图
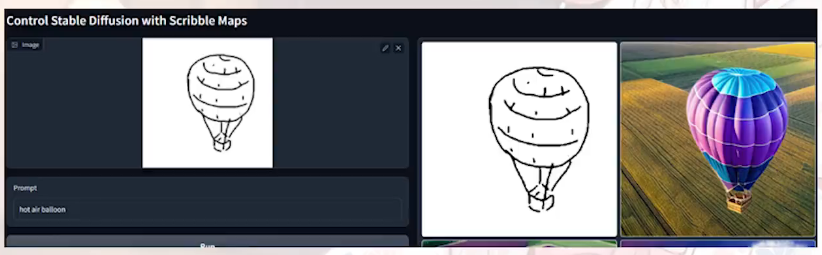
人设三视图
lora使用, 在正向Tag里最后一行加入
1 | <lora:charturnbetalora:0.2> |
这里使用 0.2-0.6 间的数字即可
高清修复 (Denoising) 设置为 0.6
更新
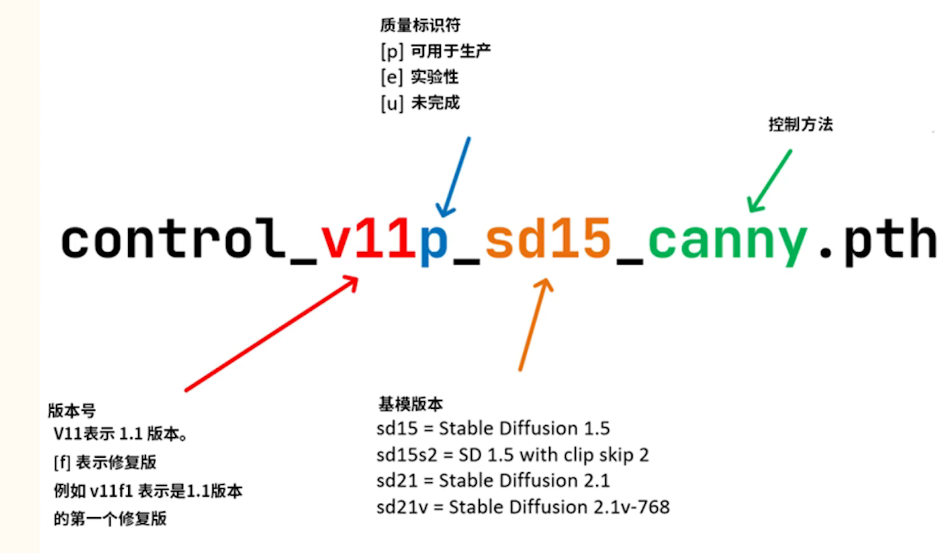
模型命名方式
Lineart 模型, 强大的线稿上色能力

Instruct Pix2Pix, 按照指令/tag 局部整体操纵图像程度的能力. eg. 变为夜晚. 效果不稳定

Tile 模型, 增加局部细节, 根据画面自动退段内容, 修复直接拉大分辨率导致的细节丢失. 如果局部内容与全局提示词不匹配, 则忽略掉提示词, 根据局部信息推断当前去雨内容
Shuffle 打乱重建 / 风格迁移
更换模型
常见模型: 大模型, Embedding 模型, Hypernet 模型, LoRA 模型. 常用的是大模型和 LoRA 模型
ADetailer
[教程1](拒绝脸崩 stable diffusion修脸大法 ADetailer脸部修复插件教程_哔哩哔哩_bilibili), [教程2](【AI绘画】Stable Diffusion中级教程03——局部重绘(利用SD进行换脸) - 知乎 (zhihu.com))
用于局部重绘, 尤其在远景镜头的人像崩掉的情况
人脸崩掉如何解决?
- 拉成近景, 不要全身像
- 拉高分辨率, 提高对人脸的采样
- 局部重绘: 一张人脸一张人脸重绘
- ADetailer: 群体人脸重绘
局部重绘
- 输入进局部重绘
- 画笔涂掉想要重画的区域 (即蒙版)
- Tag 中加入想重新生成的词
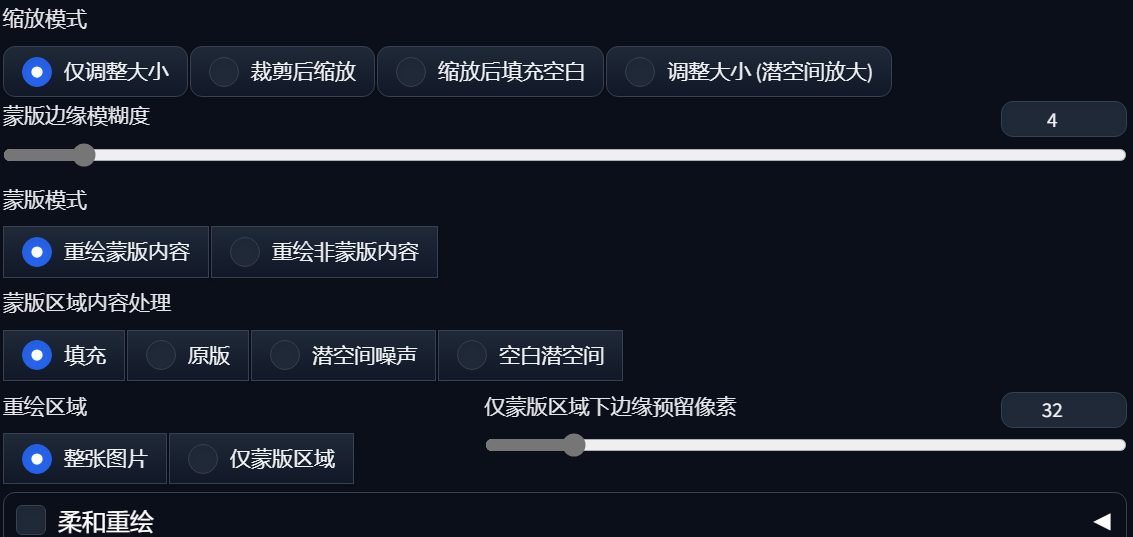
缩放模式
参考图与重绘后的图片尺寸不一致时, 可以选择 “拉伸模式”, “裁剪模式”, “填充模式” 或 “调整大小模式” 来处理图片
蒙版边缘模糊度
边缘无法准确选中, 使用蒙版模糊以羽化蒙版边缘, 使重绘部分与原图周围更加贴合. 0 最小, 最锐利
人话: 画出来的边缘不那么锐利, 与原图有过渡
蒙版模式
可以选择重绘蒙版内容或重绘非蒙版内容.
蒙版区域内容处理
可选 “填充”, “原图”, “潜变量噪声”, “空白潜空间”
- 填充: 先将蒙版内容模糊化, 再一步步去噪生成新图片
- 原图: 在原图基础上生成新图片
- 潜变量噪声: 将蒙版部分变噪声, 再重新生成图片
- 空白潜空间: 即潜变量噪声为 0, 相当于填充模式, 采用模糊化蒙版颜色后进行去噪的过程
大部分情况下用原图, 因为修改非蒙版内容时要保留脸型
重绘区域
可选 “全图重绘” 和 “仅蒙版区域”
- 全图重绘: 蒙版的原图尺寸下, 重绘蒙版区域. 此时重绘区域分辨率与原图一致, 所以重绘内容与原图融合得更好, 缺点是不够细节
- 仅蒙版区域: 先将蒙版区域放大到出图尺寸的大小, 再重绘蒙版区域. 这会生成更丰富的细节, 但细节太多会与原图融合得不好
柔和重绘
根据蒙版不透明度, 将原始画面与重绘内容无缝融合. 推荐在高蒙版边缘模糊度下使用
ADteiler
同时加载模型的数量等于使用单元的数量
可以通过同时加载多个模型来同时修复多个人脸和手部图片
模型置信阈值: 降低以识别更多的人脸, 提高以更准确地识别人脸
脸部修复推荐使用 face_yolo8n_v2.pt, 对二次元和真人都同时有效. mediapipe 开头的模型大多对真人有效. 若修复人脸, 在使用上面脸部修复模型的下方输入 “detail face”; 若换表情, 可以输入如 “laugh”, “cry”, “sad” 等词来改变表情
ControlNet
[参考教程](30分钟零基础掌握ControlNet!绝对是你看过最好懂的控制网原理分析 | 基本操作、插件安装与5大模型应用 · Stable Diffusion教程_哔哩哔哩_bilibili)

需要选中 “启用” 才会使用 ControlNet
基本控制参数
- 完美像素模式 Pixel Perfect: 自动计算预处理器产出图像最合适的分辨率, 避免因为尺寸不合导致图像模糊变形
- 允许预览Allow Preview: 增加预览器窗口, 展示信息图
- 控制强度Control Weight:决定控制效应的强度. 多数维持 1 不变
- 引导介入时机Starting Control Step:图像扩散过程中开始加入 ControlNet 的时间. 更改会赋予模型更高的自由度
- 引导终止时机Ending Control Step: 图像扩散过程中结束加入 ControlNet 的时间. 更改会赋予模型更高的自由度
控制模式
可选 “均衡”, “更偏向提示词”, “更偏向 ControlNet”. 用以控制在提示词的影响和 ControlNet 的信息间更倾向于哪一个. 多数选择 “均衡”
缩放模式
参考图与重绘后的图片尺寸不一致时, 可以选择 “仅调整大小”, “裁剪后缩放”, “缩放后填充空白” 来处理图片
预处理器参数
选择好预处理器后, 下面根据预处理器的不同会有不同参数设置. 例如:
- 控制权重
- 引导介入时机
- 引导终止时机
- 预处理器分辨率 Preprocessor Resolution: 一般不需要很大, 若预处理器为 Canny, Lineart, Depth 等需要很高精度的预处理器, 可以调大
常用控制模型
OpenPose
了解很多了, 过
Depth
生成富有空间感的多层次场景
四种预处理器, 以 depth_leres++ 效果最精细, 处理时间最长
Canny
提取边缘特征并输入图像. Canny 可以保留一些需要精确表达的内容, 如文字和标识. 如果识别不到部分线条, 可以调低以下特定参数
- Canny Low Threshold: 低阈值, 识别暗部
- Canny High Threshold: 高阈值, 识别亮部
可以用于线稿上色. 如果输入线稿是白底黑线的, 要将预处理器设置为 “invert”(反转). 这是因为线稿本身仅有边缘, Canny 再提取边缘会使本来清晰的边缘变模糊, 重复提取造成模糊.
Lineart 是 Canny 的高级实现, 基于动漫风格的线稿实现上色功能的预处理器
Soft Edge(柔和边缘)
也称 HED (holistically-nested edge detection) 整体边缘线条检测, 作用与 Canny 类似, 但是线条边缘会更模糊一些
模型上有 hed 的模型效果会比 Pidinet 好, safe是他们的精简版
Scribble
比 Soft Edge 还要自由奔放
Brightness
用于生成 3D 光影图片. 输入一张黑底白字的照片, 然后生成照片
采样器sampler
[参考教程](救老命了!Stable Diffusion 入门之30+采样方法 (Sampler)详解 - 知乎 (zhihu.com))
主要的采样方法可分为 “老式采样器”, “DPM采样器”, “新式采样器”
总结
祖先采样器
- “a”: 祖先采样器, 每一个采样步骤中向图像添加噪声, 采样结果有随机性. 缺点是图像不会收敛, 实现动画时避免使用
- “SDE”: 也是用了祖先采样, 生成图像不收敛
Karras 采样器
- “Karras”: 使用 [Karras 文章]([2206.00364] Elucidating the Design Space of Diffusion-Based Generative Models (arxiv.org))推荐的操作, 在噪声步长接近尾声时更小, 有助于提高图像质量
最终结论
- Euler, Euler a: 更快获得简单结果
- DPM++ 2M Karras: 推荐算法, 速度快, 质量好, 推荐步数 20-30
- DPM++ SDE Karras: 图像质量好但是不收敛, 速度慢, 推荐步数 10-15
- DPM++ 2M SDE Karras: 2M 和 SDE 的结合算法, 速度与 2M 相仿, 推荐步数 20-30
- DPM++ 2M SDE Exponential: 画面更柔和, 细节更少, 推荐步数 20-30
- DPM++ 3M SDE Karras, DPM++ 3M SDE Exponential: 3M 系列, 步数要 30 步以上, 且 CFG 要低一些
- UniPC, Restart: 更少的步数就能获得好的结果
- LCM: 配合专门的大模型使用, 6-10步可获得好结果, CFG 1-2
老式采样器
不再使用:
| DDIM | 最早的采样器,已过时 |
|---|---|
| PLMS | 最早的采样器,已过时 |
还在使用
| Euler | 经典ODE算法,欧拉采样方法,用于得到一些简单的结果 |
|---|---|
| Euler a | Euler的祖先采样器 |
| Heun | Euler 的改进版本,更准确但速度慢了一倍左右 |
| LMS | 线性多步法,与 Euler 速度相仿,但(据说)更准确。 |
| LMS Karras | LMS 的 Karras 算法 |
DPM 采样器
| DPM fast | DPM快速算法,速度和 Euler 相仿,但是生成的效果极差 |
|---|---|
| DPM adaptive | 不考虑采样步数,使用自己的自适应采样步骤,且生成时间极长 |
DPM2 方法:
| DPM2 | DPM的二代算法,但是速度比 Euler 慢了一倍左右 |
|---|---|
| DPM2 a | DPM2的祖先采样器 |
| DPM2 Karras | DPM2 的 Karras 算法 |
| DPM2 a Karras | DPM2 a 的 Karras 算法 |
2S 方法
| DPM++ 2S a | DPM单步算法,速度比 DPM2 快一点 |
|---|---|
| DPM++ 2S a Karras | 2S a 的 Karras 算法 |
2M 方法:
| DPM++ 2M | DPM二阶多步算法,相当于 2S 的升级,速度和Euler差不多 |
|---|---|
| DPM++ 2M Karras | DPM++ 2M 的 Karras 算法 |
SDE 方法:
| DPM++ SDE | 使用了祖先采样,速度比 Euler 慢了一倍左右,图像不会收敛且随着迭代步数的变化而波动 |
|---|---|
| DPM++ SDE Karras | SDE 的 Karras 算法 |
2M SDE 方法:
| DPM++ 2M SDE | 2M 和 SDE 的结合,速度和 2M 一致 |
|---|---|
| DPM++ 2M SDE Karras | 2M SDE 的 Karras 算法 |
| DPM++ 2M SDE Exponential | 2M SDE 的 Exponential 算法,画面柔和,背景更干净,但是细节会少些 |
2M SDE Heun 方法:
| DPM++ 2M SDE Heun | 2M SDE Heun 算法,速度慢 |
|---|---|
| DPM++ 2M SDE Heun Karras | 2M SDE Heun 的 Karras 算法 |
| DPM++ 2M SDE Heun Exponential | 2M SDE Heun 的 Exponential 算法,画面柔和,背景更干净,但是细节会少些 |
3M SDE 方法:
| DPM++ 3M SDE | 3M SDE 算法,速度和2M一致,但需要更多的迭代步数 (>30),CFG小一些效果更好 |
|---|---|
| DPM++ 3M SDE Karras | 3M SDE 的 Karras 算法 |
| DPM++ 3M SDE Exponential | 3M SDE 的 Exponential 算法,画面柔和,背景更干净,但是细节会少些 |
新式采样器
| UniPC | 2023 年发布的新采样器,可以在 5-10 个步骤内实现高质量的图像生成 |
|---|---|
| Restart | Stable Diffusion WebUI 1.6 新增的采样器,可以用比UniPC更少的步数生成图像 |
| LCM | Stable Diffusion WebUI 1.8.0 新增的采样器,需要配合专门的 LCM 大模型,可以在 6-10 个步骤内实现质量不错的图像生成,CFG 一般在 1~2 之间 |
Roop
勾选 "启用"
逗号分隔的面部编号Comma separated face number(s): 指定替换第几张人脸, 从左往右从 0 开始数
面部修复:可选 “none”, “CodeFormer”, “GFPGAN”, 后两者效果差不多
AnimateDiff
Text2Video 的工具
参数
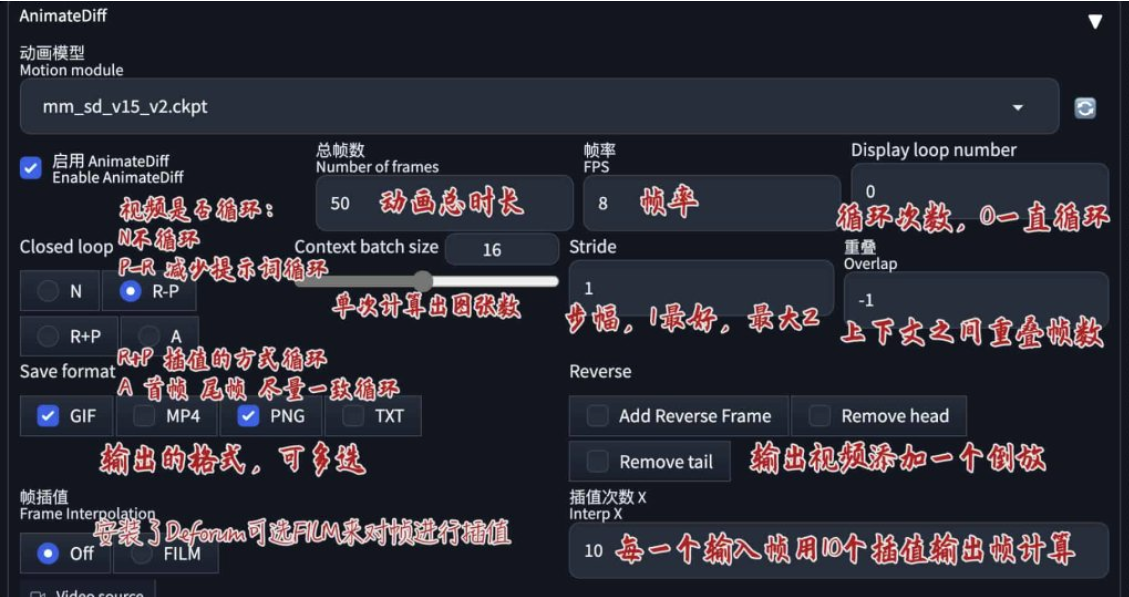
参数 (TODO: 这参数都写的什么玩意)
- 运动模块 Motion module: 可选mm_sd_v14.ckpt 和 mm_sd_v15.ckpt, v14 好像会更好
- 帧数 Number of frames: 总帧数, 至少 8 帧. 帧数为 0 时, 若有视频输入, 帧数与输入视频帧数相同. 总帧数 Number of frames 要大于上下文批量大小 Context batch size
- 每秒帧数 FPS: 调整播放速度, 至少 8 至 12 帧. 若有输入视频则与输入视频相同
- 上下文批量大小 Context batch size: 一次有多少帧传递到运动模块中. SD1.5 运动模块使用 16 帧训练, 所以该项设置为 16 时最好; SDXL HotShortXL 运动模块使用 8 帧训练, 所以对于 V1 / HotShotXL 运动模块选择 [1, 24], 对于 V2 / AnimateDiffXL 运动模块选择 [1, 32]
- 闭环 Clokse loop
- 步幅 Stride
- 重叠 Overlap
- 显示循环数量 Display loop number: 动画重复几次, 0 则一直循环
- 保存格式 Save format: 可选 “gif”, “mp4”, “webp”, “webm”, “png”, “txt”. 需要信息文本则选 “txt”, 信息文本与输出 gif 位于同一目录
闭环 Closed loop
(copied from [link](精讲stable diffusion webui的AnimateDiff动画插件 | 草凡博客 | 第 6 页 (caovan.com)))
意味着此扩展将尝试使最后一帧与第一帧相同。
- 当
Number of frames>Context batch size时,包括当 ControlNet 启用且源视频帧数 >Context batch size且Number of frames= 0 时,AnimateDiff 无限上下文生成器将执行闭环。 - 当
Number of frames<=Context batch size时,AnimateDiff 无限上下文生成器将不起作用。只有当您选择“A”时,AnimateDiff 才会将反转的帧列表附加到原始帧列表以形成闭环。
有关每个选择的说明,请参阅下文:
N意味着绝对没有闭环 – 如果Number of frames的值小于Context batch size且不为0 ,这是唯一可用的选项。R-P意味着扩展将尝试减少闭环上下文的数量。提示行程(prompt traveling)不会被插补为闭环。R+P意味着扩展将尝试减少闭环上下文的数量。提示行程(prompt traveling)将被插补为闭环。A意味着扩展将积极尝试使最后一帧与第一帧相同。提示行程(prompt traveling)将被插补为闭环。
步幅 Stride
“步幅”(Stride)是最大运动步幅的设置,用 2 的幂表示(默认:1)。
-
由于无限上下文生成器的限制,该参数仅在
Number of frames>Context batch size时有效,或者当 ControlNet 启用且源视频帧数 >Context batch size且Number of frames为 0 时有效。 -
Stride只有当为 1时,才能完全没有闭环。 -
对于每个 1≤2𝑖≤1≤2i≤
Stride,无限上下文生成器将尝试使相隔2𝑖2i的帧在时间上保持一致。例如,如果Stride为4 ,并且Number of frames为8,它将使以下帧在时间上保持一致:-
Stride== 1: [0, 1, 2, 3, 4, 5, 6, 7] -
Stride== 2: [0, 2, 4, 6], [1, 3, 5, 7] -
Stride== 4: [0, 4], [1, 5], [2, 6], [3, 7]
-
重叠 Overlap
上下文中重叠的帧数
如果重叠为 -1(默认):您的重叠将为Context batch size// 4
由于无限上下文生成器的限制,该参数仅在Number of frame>Context batch size时有效,包括当 ControlNet 启用且源视频帧数 >Context batch size且Number of frames为 0 时有效。
提示穿梭 Prompt Travelling
精确控制特定时间帧内的具体细节
- 头部提示: 确定生成的视频或 GIP 的整体外观
- 帧提示: 对于特定帧, 展示的内容的提示
- 尾部提示: 动画结束时的内容
举个例子:

画面分区 Latent Couple + Lora修饰限制 Composable Lora
[参考教程](【NovelAI】教程:使用Latent Couple+Composable Lora+角色Lora绘制双人图吧! - 哔哩哔哩 (bilibili.com))
画面分区 Latent Couple
作用: 对绘制进行分区, 对不同分区使用不同的 Lora
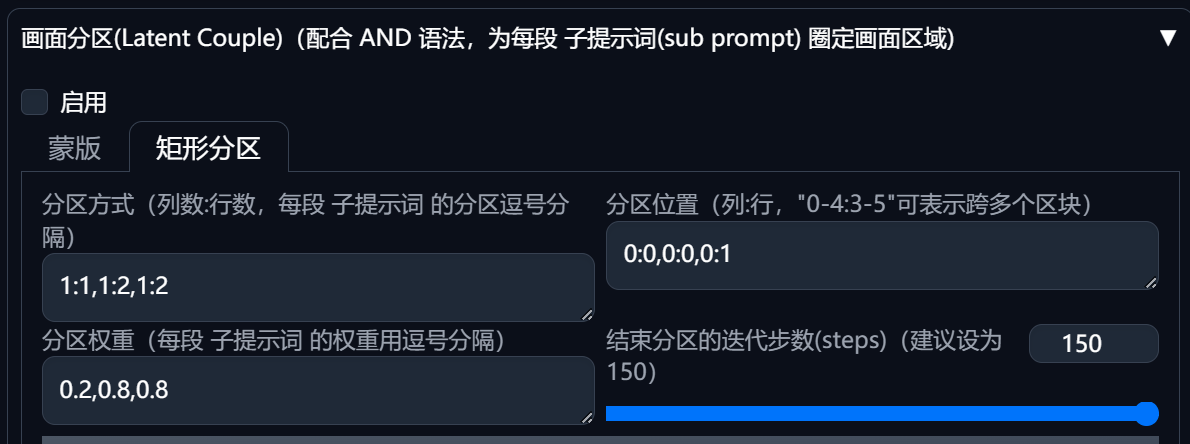
参数:
-
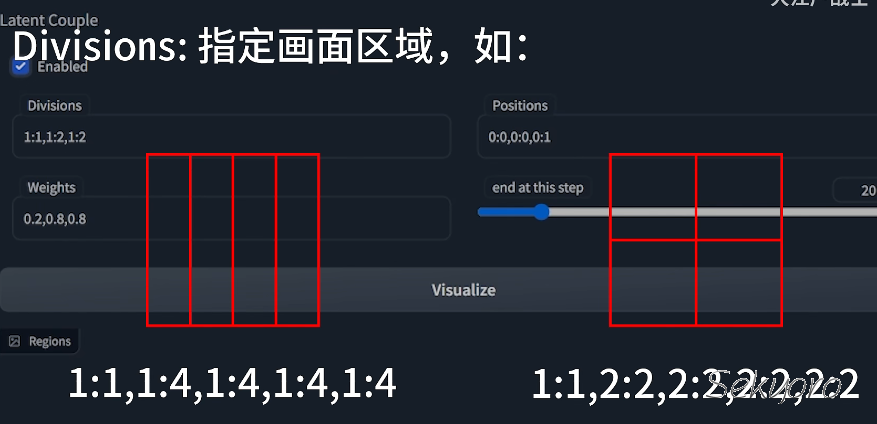
分区方式 Divisions: eg. “1:1, 1:2, 1:2”, “1:1” 表示整幅画面, “1:2” 表示一幅画分为一行两列. 同理 “1:1, 2:2, 2:2, 2:2, 2:2”
-
位置 Positions
-
权重 Weights
以水平分区为例, 假设我们需要绘制n个人物,则Divisions中填写1:1,1:n,1:n,…,1:n(n,1:n),Positions中填写0:0,0:1,0:2,…,0:n-1,Weights中填写0.2,0.8,0.8,…0.8(n个0.8)
正面 tag 要用特殊的方式写, 例如
1 | 全局tag |
Lora修饰限制 Composable Lora
作用: 避免不同 Lora 间的污染. 与上面的插件必须同时使用
实战
可以进行竖直分区和水平分区. 以水平分区为例, 假设要绘制 N 个任务, 在 Divisions中填写
什么玩意啊这是 :(